Pytorch for dummy

Originariamente impletato da META ora fa parte della Linux foundation
La base di tutto è il tensore, che non è altro che una matrice (o un array) sulla quale PT consente tutta una serie di operazioni, un po' come numpy, es:

es:

Layer della rete neurale
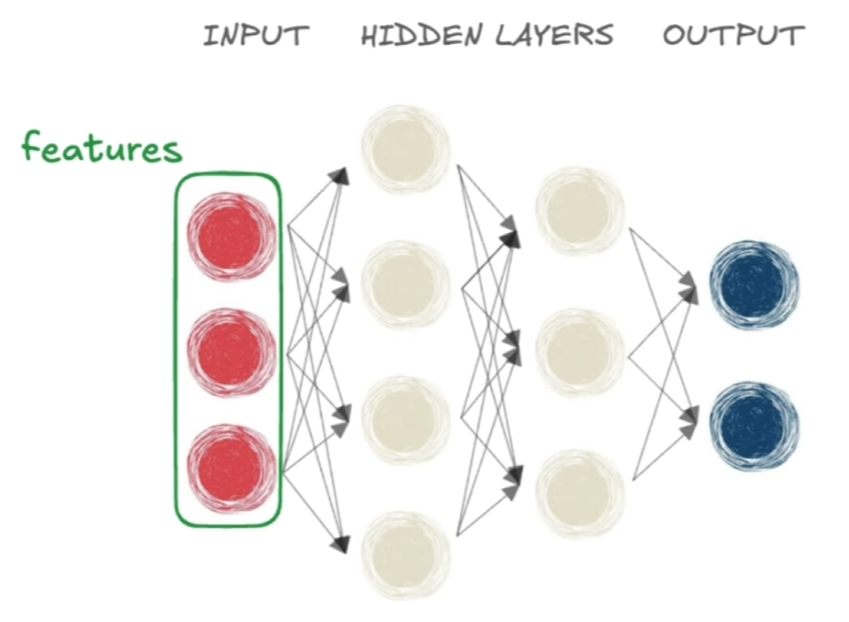
la parte in rosso sono gli input della rete, detta "features", la parte in grigio sono i layer "nascosi", mentra la parte di blu è l'output layer ovvero l'output desiderato.
Classificatori
Le funzioni possono essere:
- Sigmoid per la classificazione binaria (un unico output con un valore compreso tra 0 e 1)

- Softmax per la multi classificazione, va messo come ultimi layer della rete neurale. (dove l'ultimo livelo di neurino definice il numero di valori da classificre)

- yy per la regressione, ovvero per predirre un flusso continuo di valori numerici, in questo caso non verrò inserita nessuna funzione di attivazione


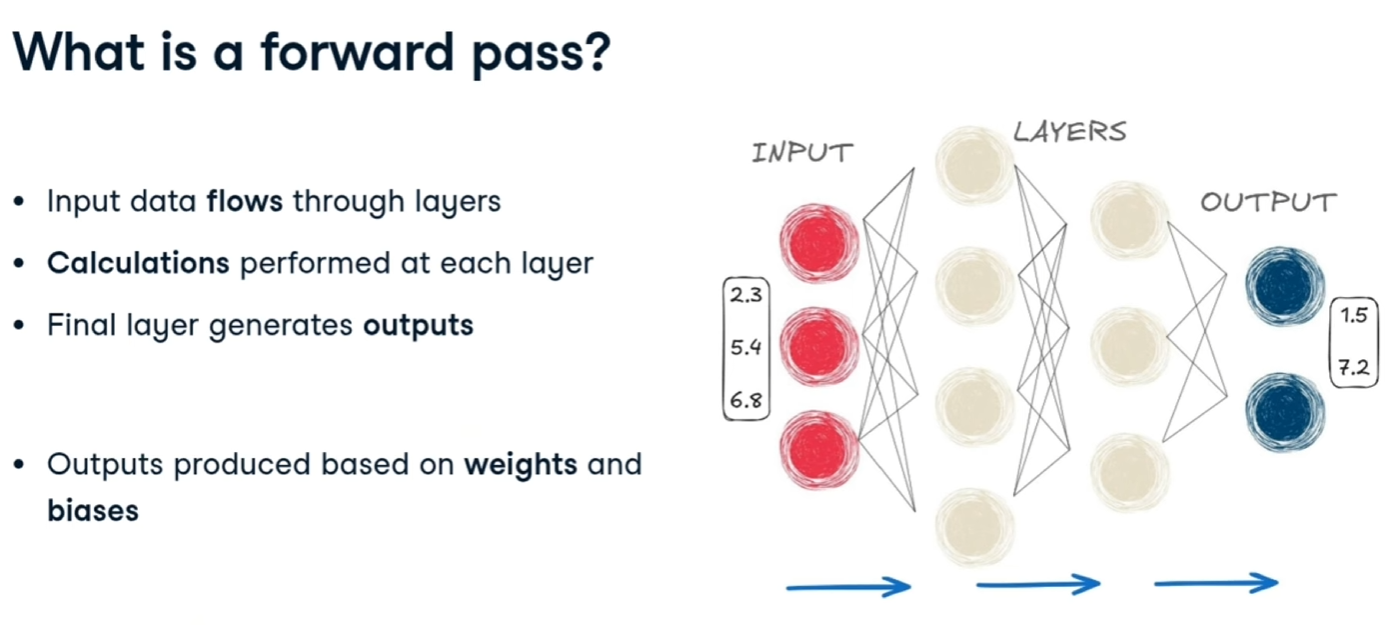
Forward pass
è l'operazione di passaggio dei pesi e del bias da un layer della rete a quello successivo
Loss function
La LF indica quanto il modello è efficace nel predirre i valori durante la fase di training.
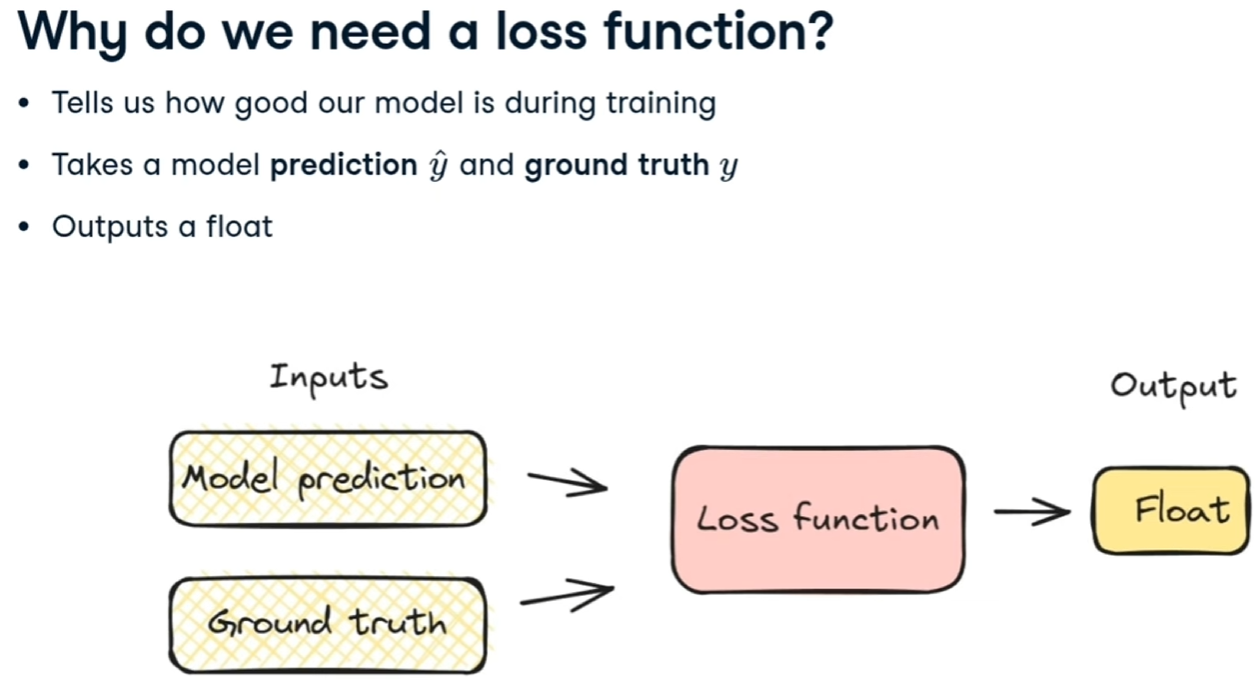
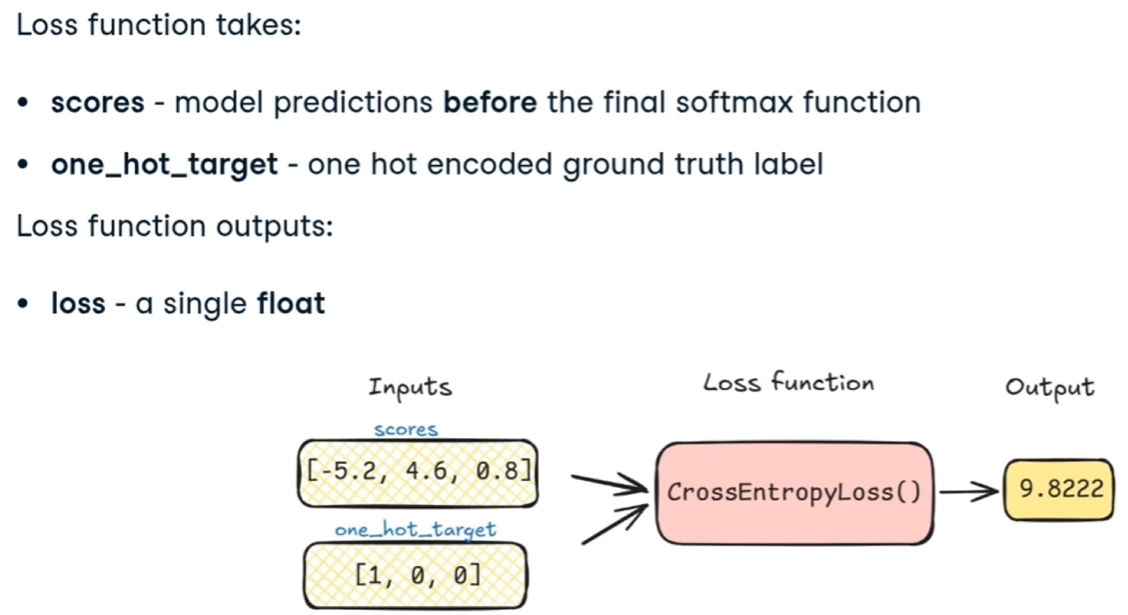
La funzione di "loss" indicata come F, riceve in input i valori corretti associati alle features utilizzate durante il training e quelli generati dal modello -> F(y,y')
L'outuput è un valore numerico

Una delle funzioni di loss function è la CrossEntropyLoss che vuole in input i valori calcolati dalla rete e le label che rappresentano il valore "vero". L'ouput è il valore di "loss" vero e proprio che, attraverso la backpropagation bisogna minimizzare.
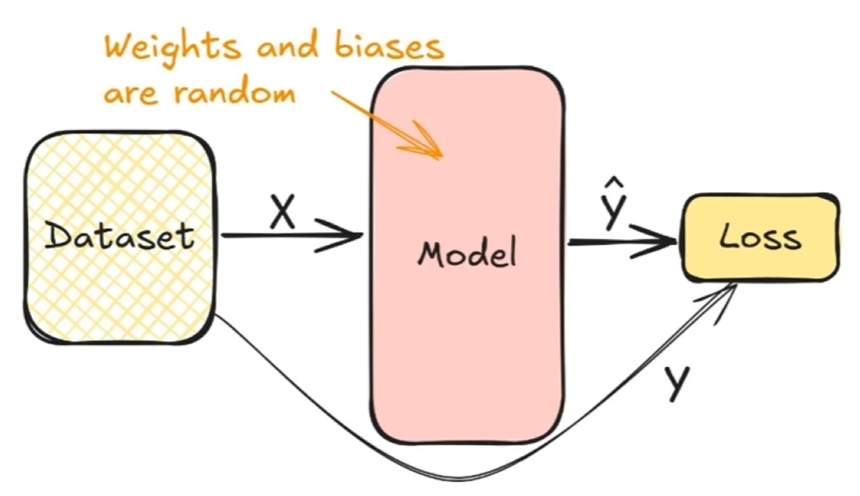
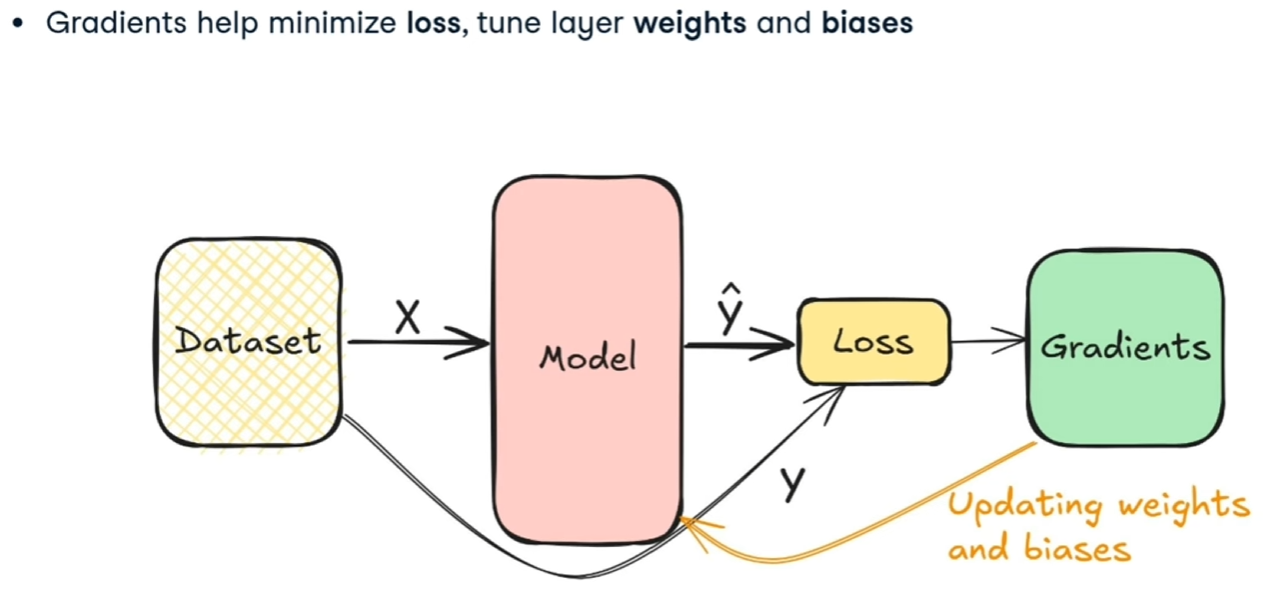
La Backpropagation
Una volta calcolati i pesi e i bias della rete neurale, si prende il valore generato y' e si effettua un'operazione di backpropagation che, attraverso il calcolo della discesa del gradiente va a ricalcolare i pesi e i bias a ritroso per ciascun layar, al fine dir minimizzare l'errore.
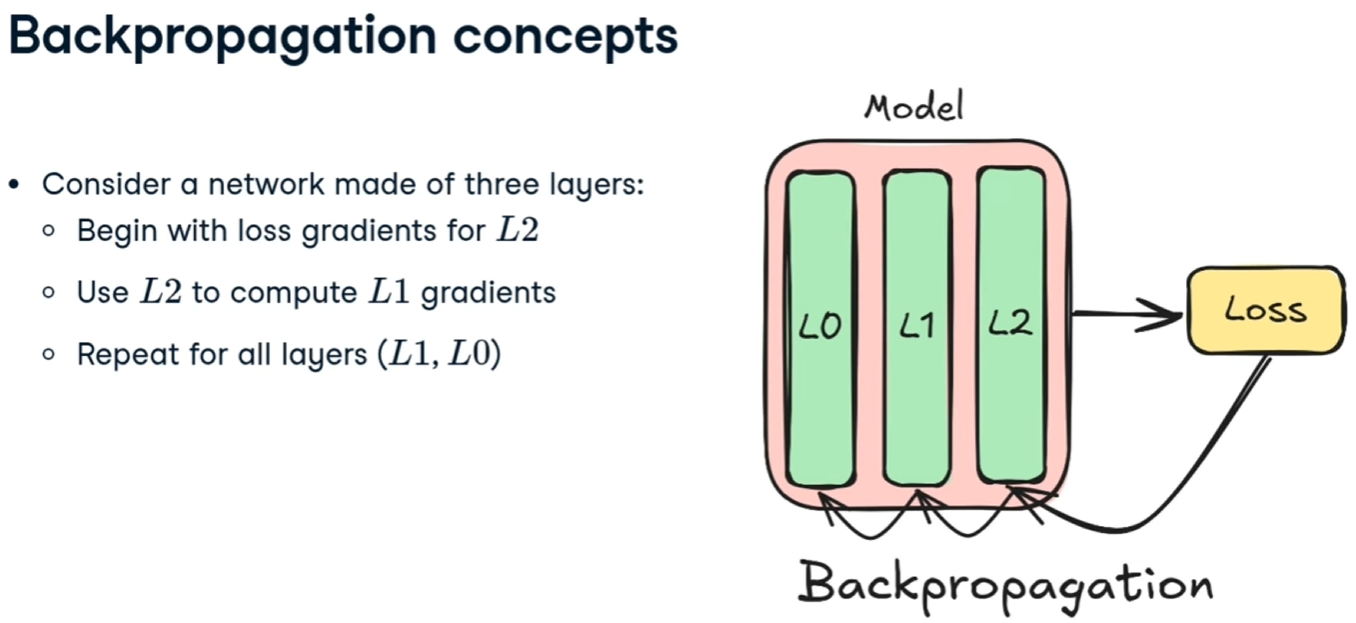
vediamolo in PT:

Preparazione dei dati per il training
Ci sono 4 passi fondamentali prima di "allenare" la rete neurale, ovvero:
prendiamo per esempio un dataset di animali dove le prime colonne (esclusa la zero che è puramente decrittiva) rappresentano le "features" mentre l'ultima indica il tipo di animale:
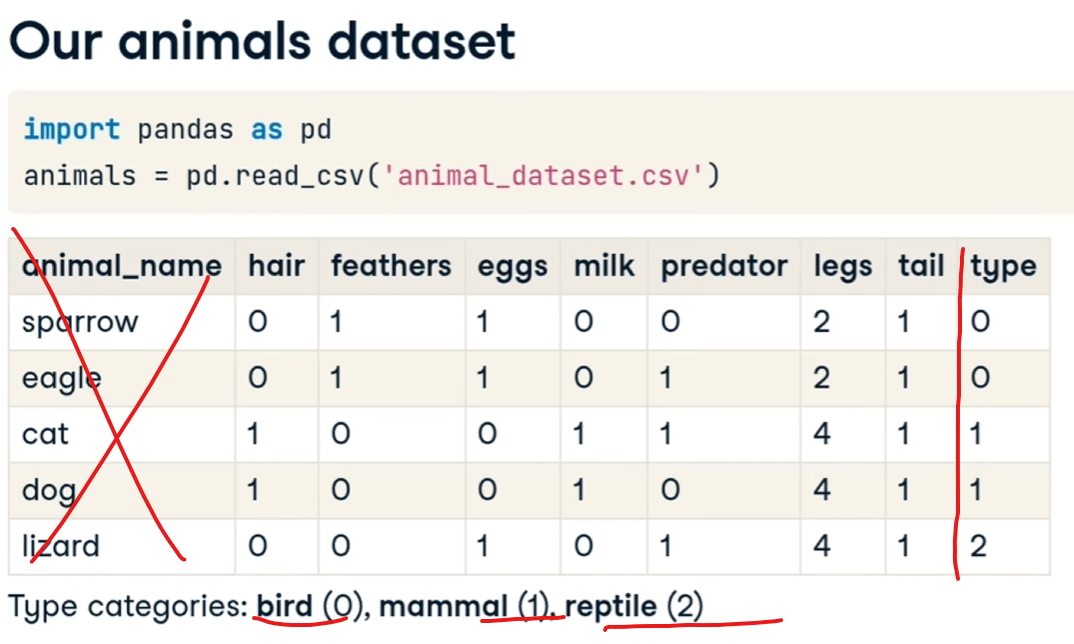
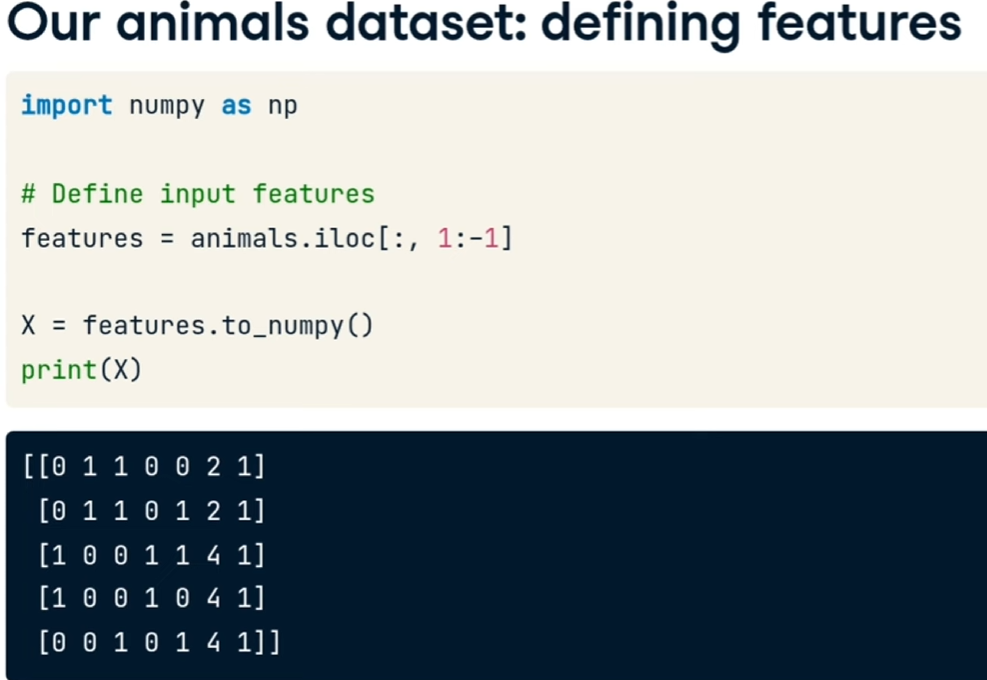
selezioniamo le fetures:
ora le labels

Ora utilizziamo l'oggetto TensorDataset per caricare le x e le y:

ora creiamo il dataloader per gestire il carico dei dati efficacemente durante il training

avendo setto il batch size a 2 ad ogni iterazione del dataloader estrarrò solo un bach di due elementi (in questo 2 carratteristiche di animali e il tipo), come sotto riportato:
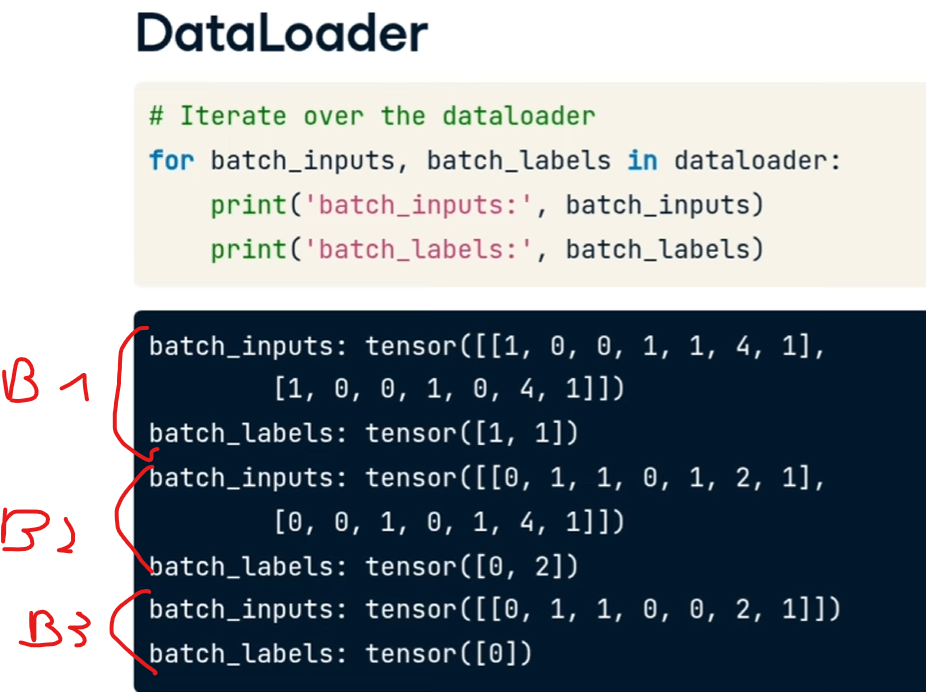
essemdo solo 5 animali si può notarer come l'ultimo batch contenga un solo animale.
Quindi il cliclo for fa passare tutto il dataset.
Training
ora possiamo procedere con il training, che consiste in:

Il training è molto importante perchè consenti di minimizzare la loss e di appore delle modifiche al training stesso.
Regressione
La regressione consente di avere un valore lineare come output.
Per la regressione so utilizza in genere la funzione di loss MSE (mean square error)

facciamo un esempio di regression i gli stipendi dei data scientist:
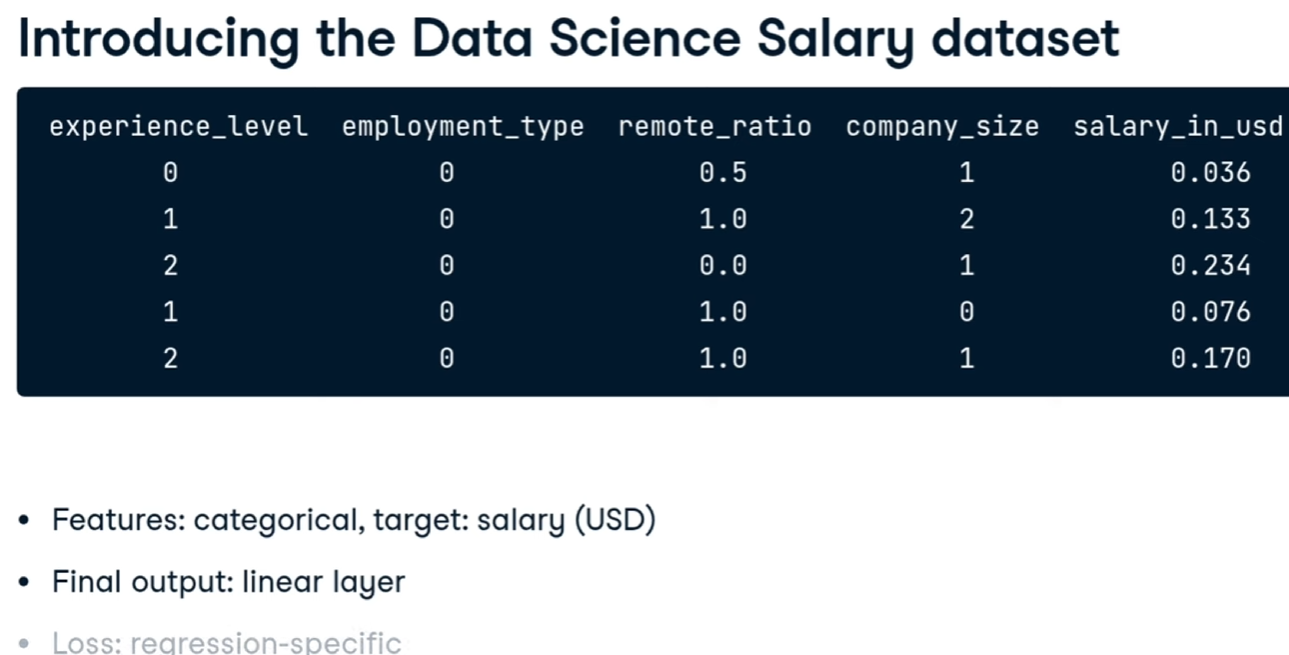
creiamo la rete neurale

adesso loppiamo su tutto il dataset
# The training loop
for epoch in range(num_epochs):
for data in dataloader:
# va azzerato ad ogni epoca
optimizer.zero_grad()
# Get feature and target from the data loader
feature, target = data
# Run a forward pass
pred = model(feature)
# Compute loss and gradients
loss = criterion(pred, target)
loss.backward()
# Update the parameters
optimizer.step()Utilizzo Softmax vs ReLU.
E' emerso che per gli hidden layer è meglio utilizzare la funzione di attivazione ReLU, mentre per l'output layer si può utilizzare anche la Softmax.
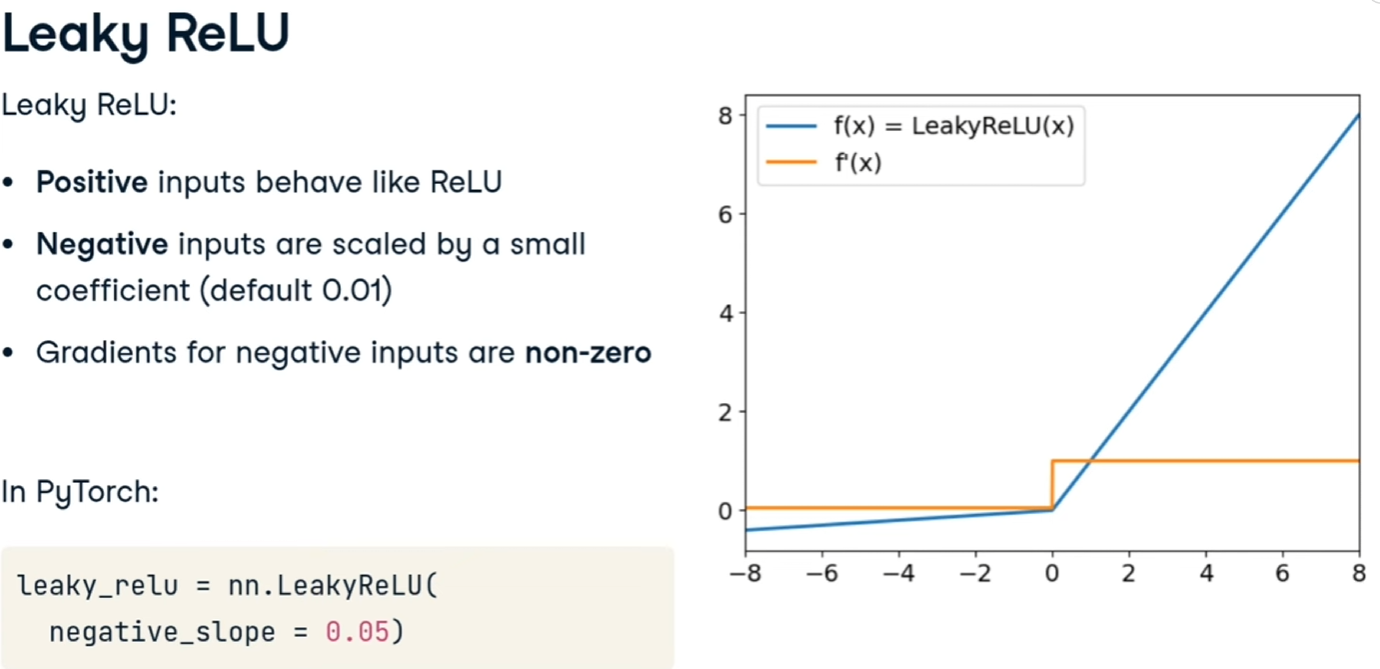
Leaky ReLU
Migliora la ReLU moltiplicando i valori di input per un coefficiente che evita i casi di disattivazione totale del neurone che causa lo stop dell'apprendimento.
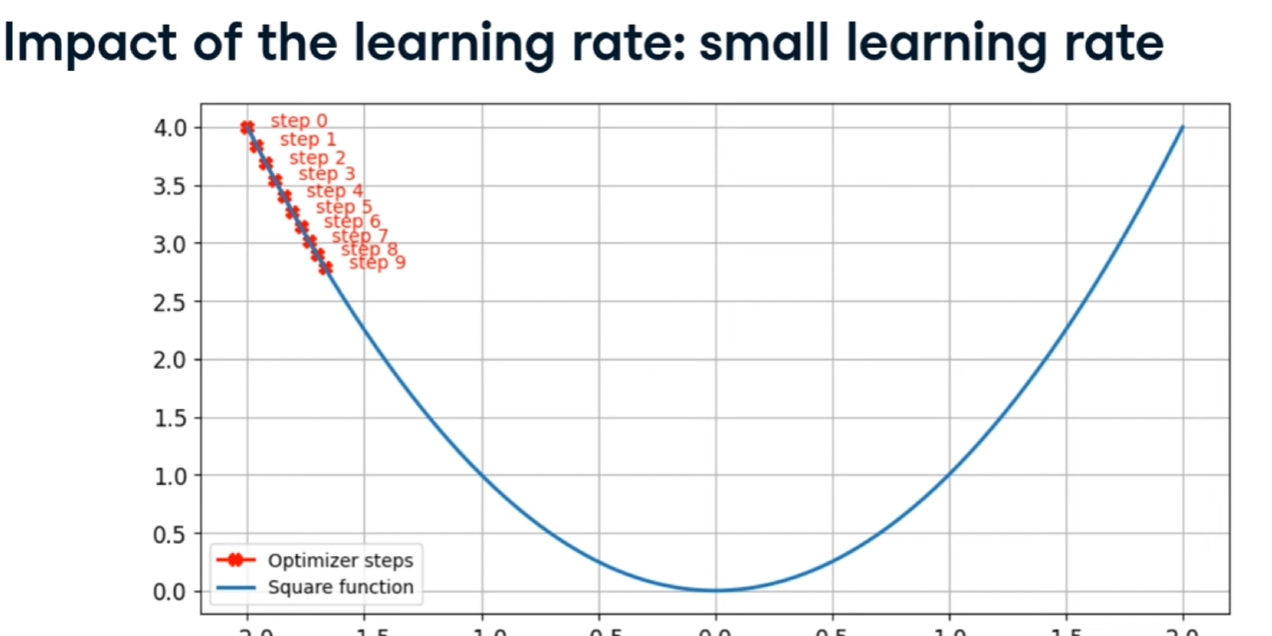
Learing rate e momentum
Il LR è il passo utilizzato per arrivare al mimimo durante la fase della discesa del gradiente, se è troppo piccolo non arrivieremo al minimo, come qui:
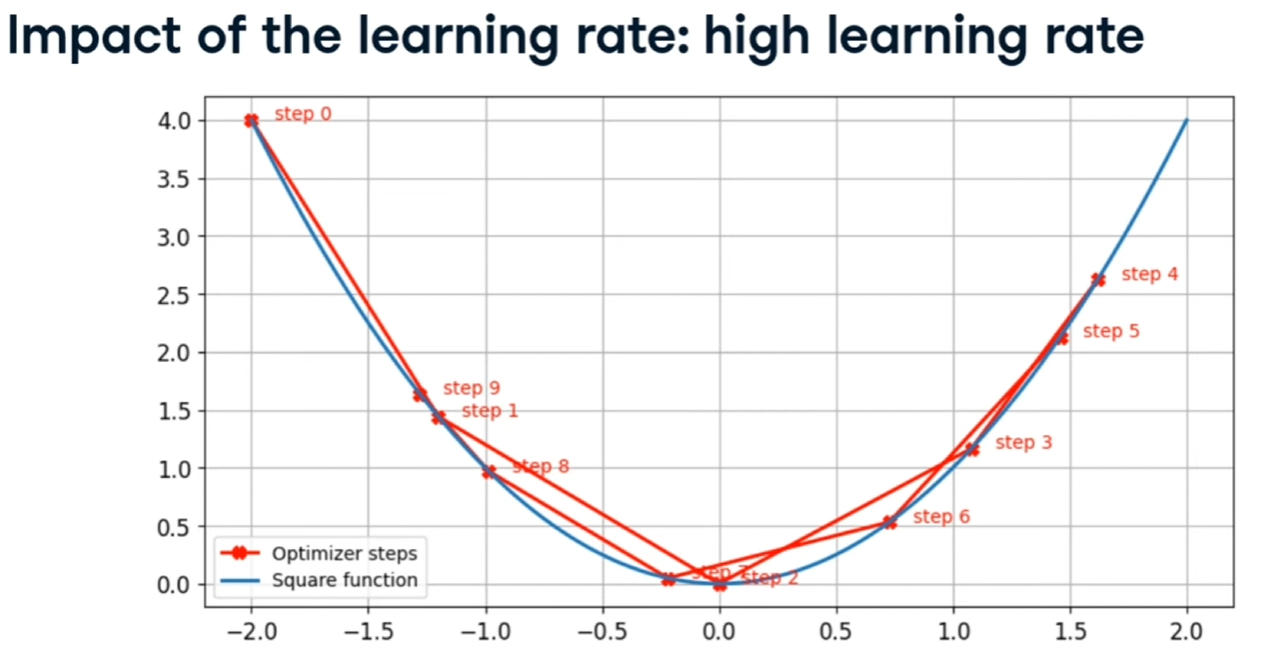
se è troppo grande, continua a rimbalzare senza trovare cmq il minimo, come qui:
Il "momento" invece rappresenta l'inzeria con la quale si effettuano i passi, serve per evitare di fermarsi ad un "minimo locale", in sintesi:

Valutazione del modello
https://www.youtube.com/watch?v=IFsVsXAqPto
47:37 Evaluating Models with Training and Validation Data