Le basi2
Il task di controllo è sostanzialmente descritto dal processo decisionale di Markov dove un set di possibili stati e azioni ritornano un reward e una probabilità di passaggio ad uno stato all'altro. Il task nella pratica è un "compito" o una simulazione che per essere svolta (risolta) implica l'utilizzo dell'MDP.
NB: Il processo decisionale di Markov (MDP) asserisce che il passaggio allo stato successivo T+1, dipende esclusivamente dallo stato attuale T e non dagli stati precedenti. Quindi il processo NON ha memoria.
Tipologie di processi decisionali di Markov
Esistono due tipologie di MPD, il processo a stati finiti e quello a stati infiniti.
Nel MDP finiti gli stati finiti hanno un numero finiti di stati definiti dall'ambiente, es. l'uscita da un labirinto di 5 caselle x 5. In questo caso abbiamo 25 stati e 4 azioni (su, giù, dx e sx)
Nel MDP a stati infiniti, invece, l'ambiente appunto può restituire infiniti stati a fronte di infinite azioni, pensiamo per es. il sistema di guida automatica di una macchina dove l'azione es. girare il volante, è un valore continuo così come la scelta della velocità dell'auto.
Episodi
MDP definisce anche degli "episodi" in particolare:
Nel MDP episodico un episodio termina a determinate condizioni. Es. nel gioco degli scacchi quando la giocare da scacco matto.
Nel MDP continuo, il processo non ha fine, semplicemente continua ad esistere all'infinito in quanto non esiste uno stato fine.
Traiettoria ed episodio
La traiettoria è il movimento che l'agente compie per muoversi da uno stato all'altro. La traiettoria è definita dal simbolo greco 
L'episodio è semplicemente una traiettoria che inizia in uno stato e finisce nello stato finale oltre quale non si torna indietro. es:
di cui deriva il concetto di storia, ovvero la somatoria delle osservazioni, ricompense e azioni fino all'azione finale.

Ricompensa vs Ritorno
La ricompensa (reward) viene restituita a fronte di un'azione, quindi per risolvere un task, dobbiamo massimizzare le ricompense ottenute. La ricompensa è quindi un risultato immediato. (Rt)
Invece il ritorno è la somma delle ricompense ad un determinato momento nel tempo es: G(t) = R(t+1) + R(t+2) + ... R(T) finchè il task è stato completato.
Fattore di sconto γ (gamma)
Il fattore di sconto è un incentivo per completare l'episodio nel miglior modo (più efficiente) possibile. Per ottenere questo la ricompensa dovrà essere moltiplicata per il fattore di sconto che diminuirà nel tempo all'aumentare delle azioni intraprese, rendendo le ricompense sempre più basse e quindi disincentivando le traiettorie lunghe.
Il fattore è un valore compreso tra zero e uno e viene elevato ad un esponente corrispondente dall'iesima azione fino alla fine dell'episodio.
Se γ (gamma) vale zero l'agente cercherà di prendere una ricompensa immediata, il che denota una strategia miope che non ottimizza l'apprendimento. Al contrario invece, un fattore γ gamma pari a uno, rende l'agente più "paziente" e quindi non prono ad ottimizzare gli step dell'episodio. In genere il fattore gamma viene settato a 0,99 che forza l'agente ad avere una ricompensa immediata ma allo stesso tempo lo forza ad avere una visione "a lungo termine".
In conclusione il fattore gamma indica all'agente quanto può valutare in maniera ottimali le azioni future.
Policy
La policy dell'agente è una funzione che prende in input uno stato e ritorna l'azione che va presa in quello stato. E' rappresenta dalla lettere greca pigreco ![]() .
.
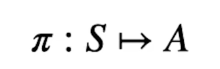
La probabilità di eseguire un'azione (a) nello stato (s) si può rappresentare come: ![]() (a|s)
(a|s)
L'azione che la policy sceglie nello stato (s) viene descritta dalla formula: ![]() (s)
(s)
Dipende quindi dal contesto, in alcuni casi si uitilzza il primo ![]() (a|S) in altri il secondo
(a|S) in altri il secondo ![]() (s).
(s).
La policy può essere di due tipi: stocastica o deterministica.
Si dice che la policy è deterministica quando viene scelta sempre la stessa azione in un determinato stato quindi stiamo parlando del caso ![]() (S).
(S).
Si dice invece stocastica quando l'azione viene scelta sulla base delle probabilità es. : ![]() (S) = [0.3, 0.2, 0.5] ovvero la probabilità di effettuare una azione nello stato S, è del 30% nel primo caso, 20% nel secondo e 50% nel terzo. Quindi siamo in presenza del caso
(S) = [0.3, 0.2, 0.5] ovvero la probabilità di effettuare una azione nello stato S, è del 30% nel primo caso, 20% nel secondo e 50% nel terzo. Quindi siamo in presenza del caso ![]() (a|S)
(a|S)
Quindi bisogna trovare la policy ottimale rappresentata come ![]() * (pigreco - asterisco) che sceglie le azioni che massimizzano la somma dei fattori di sconto per le ricompense alla lunga.
* (pigreco - asterisco) che sceglie le azioni che massimizzano la somma dei fattori di sconto per le ricompense alla lunga.
Valutazione degli stati e delle azioni di un task
Per valutare il ritorno totale di un'azione nello stato:
Q![]() (s,a) = E[Gt|St=s, At = a]
(s,a) = E[Gt|St=s, At = a]
ovvero: Il valore Q di un'azione rappresenta il ritorno che ci aspettiamo se iniziano dallo stato s eseguendo l'azione a e interagiamo con l'ambiente (E) seguendo la policy ![]() fino alla fine dell'episodio.
fino alla fine dell'episodio.
L'equazione di Bellman per v(s)
Dalla prima equazione sotto riportata si evince che il ritorno atteso utilizzando la policy ottimale ![]() è dato dal ritorno dello stato T. Espandando la definzione, come si evince dalla seconda equazione, viene rappresentato il ritorno ottimale partendo dallo stato successivo fino a quello finale scontato del fattore gamma.
è dato dal ritorno dello stato T. Espandando la definzione, come si evince dalla seconda equazione, viene rappresentato il ritorno ottimale partendo dallo stato successivo fino a quello finale scontato del fattore gamma.
Veniamo quindi all'equazione generica (la quarta) che indica la probabilità di eseguire ciascuna azione sulla base della policy moltiplicata dal ritorno atesso dal eseguire l'azione.
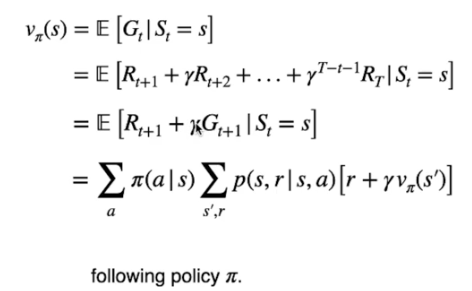
Con le nozioni di Equazione di Bellman e di Markov Decision Process possiamo finalmente sviscerare il concetto di Q-Learning.
Fin’ora abbiamo cercato di calcolare V(s), con il quale derivare la migliore azione da compiere in funzione dello stato corrente.
Ora invece di considerare il valore di ogni stato V(s), prendiamo il valore della coppia stato-azione che indichiamo con Q(s,a).
Intuitivamente, possiamo pensare al Q-value come la “qualità”dell’azione.
La nostra equazione diventa quindi:

Compiendo un’azione, il nostro agente riceve inizialmente una ricompensa R(s,a) .
Ora poiché il nuovo stato può esse uno tra molti, aggiungiamo il calcolo del valore atteso nello stato successivo.
Per cui il valore dello stato V(s) assume il massimo valore tra tutti i possibili Q-values.
Con una semplice modifica, otteniamo dunque la formula ricorsiva per il calcolo del Q-Value.

Sappi che, sebbene l’esempio sia caratterizzato da uno spazio azioni e stati discreto, lo stesso ragionamento può essere applicato a uno spazio azioni e stati continuo, generalmente dividendo il continuo in intervalli discreti.
∑ TBD
Riassumendo
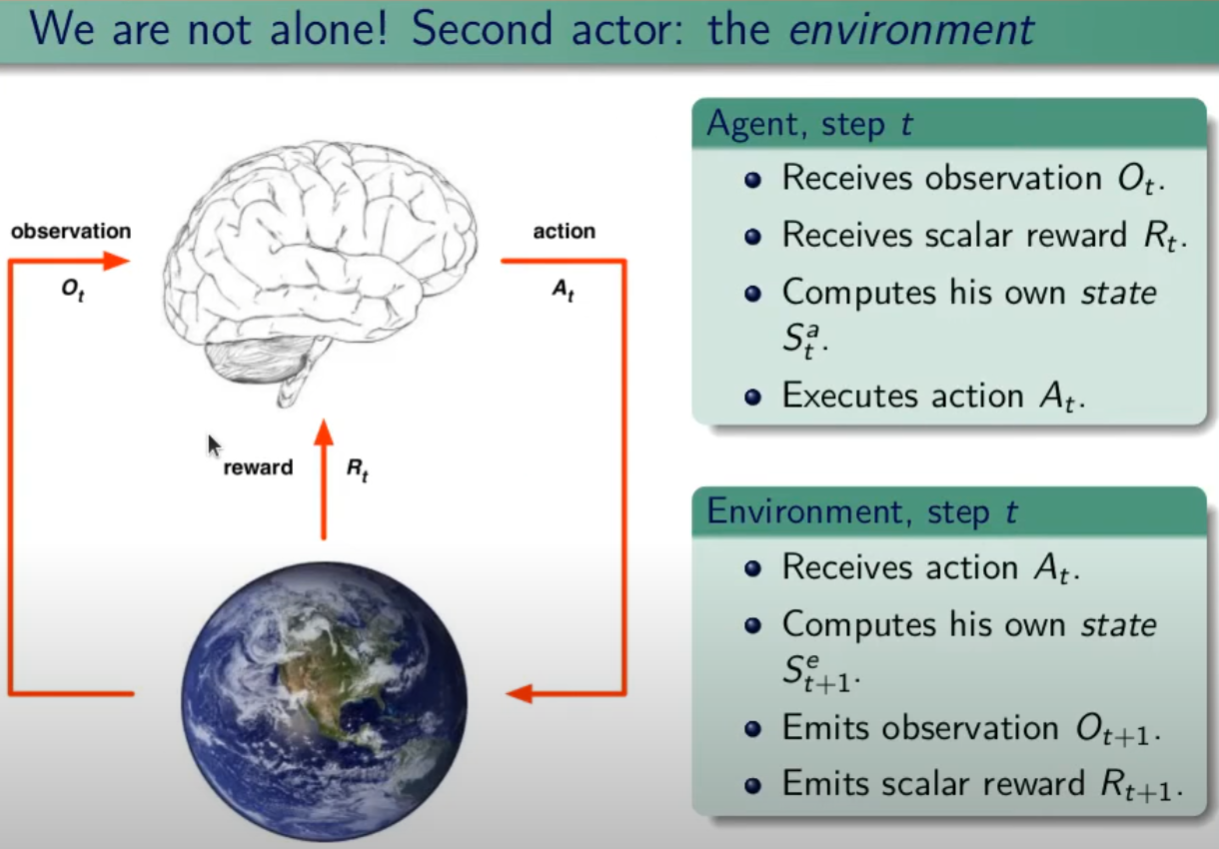
Il Reinforcement Learning è un processo caratterizzato a livello macro da due entità:
- Un ambiente (environment) che semplifica una certa realtà;
- Un agente (agent), tecnicamente un modello di AI (e.g. rete neurale) che interagisce con l’ambiente.
Ci sono altri tre termini chiave nel vocabolario del Reinforcement Learning che bisogna necessariamente conoscere.
L’agente interagisce con l’ambiente, per realizzare ciò, compie azioni (actions) che alterano l’ambiente (anche se non è sempre così) generando un nuovo stato (state), ottenendo una ricompensa (reward) che può essere negativa o positiva in base all’effetto dell’azione, e in funzione del risultato desiderato.
Compiendo azioni e ottenendo ricompense, l’agente elabora una strategia ottimale per massimizzare la ricompensa nel tempo. Questa strategia è definita policy, ed è una funziona matematica a parametri ottimizzati.
Bellman Equation per Q-Learning
L’Equazione di Bellman è un concetto fondamentale nel Renforcement Learning,
Fu introdotta nel 1954 dal Richard Bellman, conosciuto come il padre del Dynamic Programming, in una pubblicazione intitolata The Theory of Dynamic Porgramming.
Partiamo da un Toy Problem, un problema piccolo e utile solo a capire i concetti di fondo.
Consideriamo un piccolo robot che debba raggiungere la posizione finale di un percorso evitando gli ostacoli:

Potremmo quindi configurare un sistema a ricompense specifico per l’ambiente tale per cui:
- -1 per ogni step (Per incoraggiare l’agente a raggiungere l’obiettivo percorrendo la tratta più breve)
- -100 per ogni mina
- +1 per ogni fulmine
- +100 per il raggiungimento della fine.
Per risolvere questo problema, dobbiamo introdurre il concetto di Q-Table.
Q-Table
Una Q-Table è una lookup table che calcola il valore atteso delle ricompense future per ogni azione in ogni possibile stato. Questo permette all’agente di scegliere la migliore azione in ogni stato.
Il nostro ambiente ha 4 possibili azioni (sopra, sotto, destra, e sinistra) e 5 possibili stati (inizio, vuoto, fulmine, mina, fine).
La domanda è dunque: come calcoliamo la massima ricompensa possibile per ogni stato, ovvero i valori della Q-Table?
Abbiamo bisogno di un processo iterativo che faccia uso del Q-Learning algorithm, il quale a sua volta si appoggia all’equazione di Bellman.
E il cerchio si chiude.
L’Equazione di Bellman per sistemi deterministici è la seguente:

In cui abbiamo:
- s – State
- α – Action
- R – Reward
- γ – Discount factor
Il fattore di sconto è necessario per tarare la variazione della ricompensa nel tempo, comunicando all’agente quanto sia rilevante la ricompensa presente rispetto a quella futura.
C’è però una questione limitante nell’applicare l’equazione a qualsivoglia ambiente.
La formula funziona solamente quando è noto lo stato successivo, informazione spesso sconosciuta e anzi dipendente dall’azione compiuta.
Abbiamo quindi bisogno di un sistema per modellare ambienti in qualche modo legati a un fattore casuale, non prevedibile.
Ora che abbiamo un’infarinatura sul concetto di Q-Table, passiamo quindi al prossimo: i Markov Decision Processes
Markov Decision Processes (MDPs) in Q-Learning
Dobbiamo distinguere due tipologie di ambiente:
- Ambiente Deterministico, per ogni azione compiuta dall’agente la probabilità che questa avvenga correttamente è massima (100%)
- Ambiente non deterministico, per ogni azione compiuta dall’agente la probabilità che questa avvenga è influenzata da un fattore casuale, ed è quindi incerta.
Ora possiamo allora introdurre il concetto di processo di Markov e processo decisionale di Markov.
Il Markov Decision Process (MDP) o processo decisionale di Markov è un modello di gestione dello stato di transizione di un agente in un ambiente dinamico e casuale, dunque non deterministico.
Fornisce un modello matematico per modellare un processo decisionale in quelle situazioni in cui il risultato è parzialmente casuale (random), e in parte sotto controllo di un decisore (decision maker).
Una definizione molto comoda per compiacere il nostro interlocutore, ma poco utile per comprendere a fondo il significato di questo concetto.
Scopriamo insieme in cosa consiste il Markov Decision Process, e sopratutto perché sia importante.
Markov Decision Process
Per capire a fondo cosa sia un processo decisionale di markov dobbiamo fare chiarezza su almeno due conceti:
- La catena di Markov, o Markov chain
- La proprietà di Markov o Markov property
Iniziamo dal primo.
Markov Chain
Nei primi anni del secolo scorso, il matematico russo Andrej Markov studiò i processi stocastici, che involvono un elemento di casualità, senza memoria, chiamati catene di Markov o Markov Chains.
Un tale processo ha un numero fisso di stati, ed evolve in modo casuale da uno stato all’altro, a ogni step.
La probabilità che l’evoluzione avvenga dallo stato s a quello s’ è fissa e dipende unicamente dalla coppia (s, s’) e non dagli stati passati, ergo per cui definiamo il sistema come privo di memoria.
Privo di memoria?
No, non ha bevuto la sera prima e dimenticato la festa in spiaggia tornando a casa con un male alla testa da Guiness World Record.
Possiamo però fare chiarezza sull’argomento.
Markov Property
Tecnicamente, l’indipendenza dagli stati passati in un processo stocastico è definita in Teoria della Probabilità come Markov property, trovi un approfondimento qui.
La Markov Property è il discriminante per distinguere i Markov Process.
Diciamo infatti che un processo stocastico si definisce Markov Process se e solo se risulti caratterizzato dalla Markov Property, e quindi se la distribuzione di probabilità condizionata dei futuri stati del processo (condizionata su entrambi gli insiemi di stati futuri e passati) dipende unicamente dallo stato presente e non dalla sequenza di eventi precedenti.
Devi sapere anche un’altra cosa fondamentale.
Da un punto di vista matematico, un processo stocastico altro non è che una famiglia di variabili casuali (i.e. Il cui valore dipende da un fenomeno aleatorio, cioè casuale) indicizzate da un parametro temporale.
Distinguiamo allora un processo stocastico tempo-discreto (o tempo-continuo) a seconda che lo spazio della variabile tempo sia discreto (o continuo).
Ora hai tutti gli strumenti per capire cosa sia davvero una Markov chain: un processo stocastico tempo-discreto (i.e. Discreto nel tempo) che soddisfa la Markov property.
Le Markov chains sono utilizzate in molte aree, tra cui termodinamica, chimica, statistica e altre.
Vediamo ora cosa sia un Markov decision process.
Markov Decision Processes
Fu Richard Bellman a descrivere per la prima volta i Markov Decision Processes in una celebre pubblicazione degli anni ’50.
I Markov Decision Processes sono allora un’estensione delle Markov Chains, con due aggiunte:
- Azioni, actions (i.e. Permettono una scelta)
- Ricompense, rewards (i.e. Motivano l’agente)
Quando esiste una sola azione per ogni step, e tutte le ricompense sono uguali, il processo decisionale di Markov (Markov decision process) si riduce a una catena di Markov (Markov chain).
Osserviamo allora un esempio di Markov decision process.

Il MDP in figura ha 3 stati e al massimo 3 azioni per ogni step.
Iniziando allo stato s0 l’agente può scegliere una delle 3 azioni a0,a1,a2.
Se scegliesse l’azione a1 rimarrebbe nello stato s0 con certezza (probabilità 1.0) senza ottenere alcuna ricompensa.
Se scegliesse l’azione a0, avrebbe il 70% di probabilità di guadagnare una ricompensa di 10 punti e rimanere nello stato s0. In questo caso l’agente potrebbe optare per la medesima scelta ottenendo quante più ricompense possibili, benché a un certo punto raggiungerà lo stato s1.
Nello stato s1 le azioni sono 2: a0 e a2.
L’agente può ora scegliere di stare ripetutamente nello stato optando per l’azione a0. L’azione a2 permetterebbe invece all’agente di raggiungere lo stato s2 seppur con una ricompensa negativa di 50 punti.
Dallo stato s2 la sola azione concessa è l’a0 che riporterebbe l’agente allo stato iniziale con una ricompensa di 40 punti.
Bellman individuò un modo per stimare un parametro, l’optimal state value di qualunque stato s, espresso come V*(s) inteso come somma di tutte le future ricompense scontate (i.e. Con applicato il discount rate, spiegato in questo post) che l’agente può potenzialmente ricevere in media dopo aver raggiunto lo stato s, assumendo che agisca in modo ottimale.
Bellman dimostrò che quando l’agente agisce in modo ottimale, la Bellman Optimality Equation può essere applicata.
Si tratta di un’equazione ricorsiva che, assumendo che l’agente agisca in modo ottimale, permette il calcolo dell’optimal state value, dello stato corrente come la somma delle ricompense che potrebbe ottenere in media optando per l’azione ottimale e la stima dell’optimal state value di tutti i possibili stati a cui l’azione designata porterebbe.
Questa equazione conduce a un algoritmo in grado di stimare precisamente l’optimal state value di ogni possibile stato: inizializzando ogni parametro a zero, e aggiornandoli iterativamente usando il Value Iteration Algorithm.
Il punto di forza di questo metodo è la garanzia che i valori stimati convergano all’optimal state values di ogni stato, costituendo dunque la policy ottimale.
Processo di Markov è tale quando presenta la proprietà di Markov, quando cioè la distribuzione di probabilità dei futuri stati del processo dipendono unicamente dallo stato presente e non dalla serie di eventi a esso preceduti.
I processi decisionali di Markov costituiscono invece un framework per modellare, sotto specifiche condizioni, un atto di Decision Making, in quelle situazioni in cui il risultato è in parte casuale e in parte sotto il controllo del decision maker.
Applicando questi concetti all’Equazione di Bellman, otteniamo una variante per ambienti non deterministici:

Q-Learning
Con le nozioni di Equazione di Bellman e di Markov Decision Process sulle spalle possiamo finalmente sviscerare il concetto di Q-Learning.
Fin’ora abbiamo cercato di calcolare V(s), con il quale derivare la migliore azione da compiere in funzione dello stato corrente.
Ora invece di considerare il valore di ogni stato V(s), prendiamo il valore della coppia stato-azione che indichiamo con Q(s,a).
Intuitivamente, possiamo pensare al Q-value come la “qualità”dell’azione.
La nostra equazione diventa quindi:
Compiendo un’azione, il nostro agente riceve inizialmente una ricompensa R(s,a) .
Ora poiché il nuovo stato può esse uno tra molti, aggiungiamo il calcolo del valore atteso nello stato successivo.
Per cui il valore dello stato V(s) assume il massimo valore tra tutti i possibili Q-values.
Con una semplice modifica, otteniamo dunque la formula ricorsiva per il calcolo del Q-Value.
Sebbene l’esempio sia caratterizzato da uno spazio azioni e stati discreto, lo stesso ragionamento può essere applicato a uno spazio azioni e stati continuo, generalmente dividendo il continuo in intervalli discreti.