Dimestificazione delle serie temporali
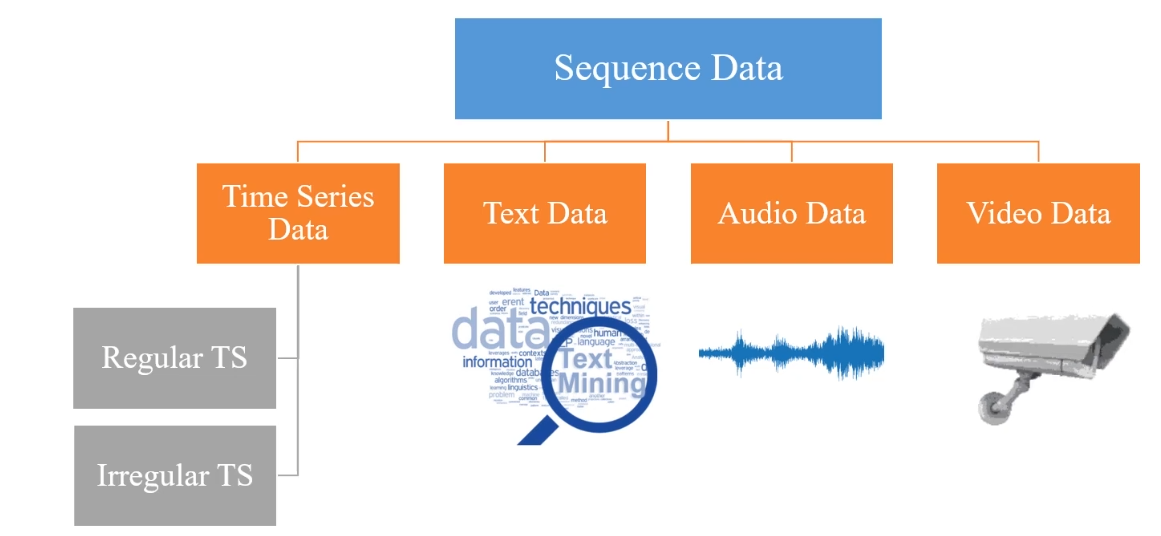
Tipologia di dati in sequenza
Dati in sequenza temporale (TS) significano dati che presentano uno specifico ordine o una sequenza nella quale vengono presentati, es:
Lo studio che verte in particolare sulle sequenza temporali che si suddividono in 1) serie TS regolari e 2) serie TS irregolari. Quelle regolari sono registrare con un timing regolare (es. ogni secondo) mentre quelle irregolari - come dice la parola - vegono registrare quando si verificano, quindi non necessariamente con cadenza regolare.
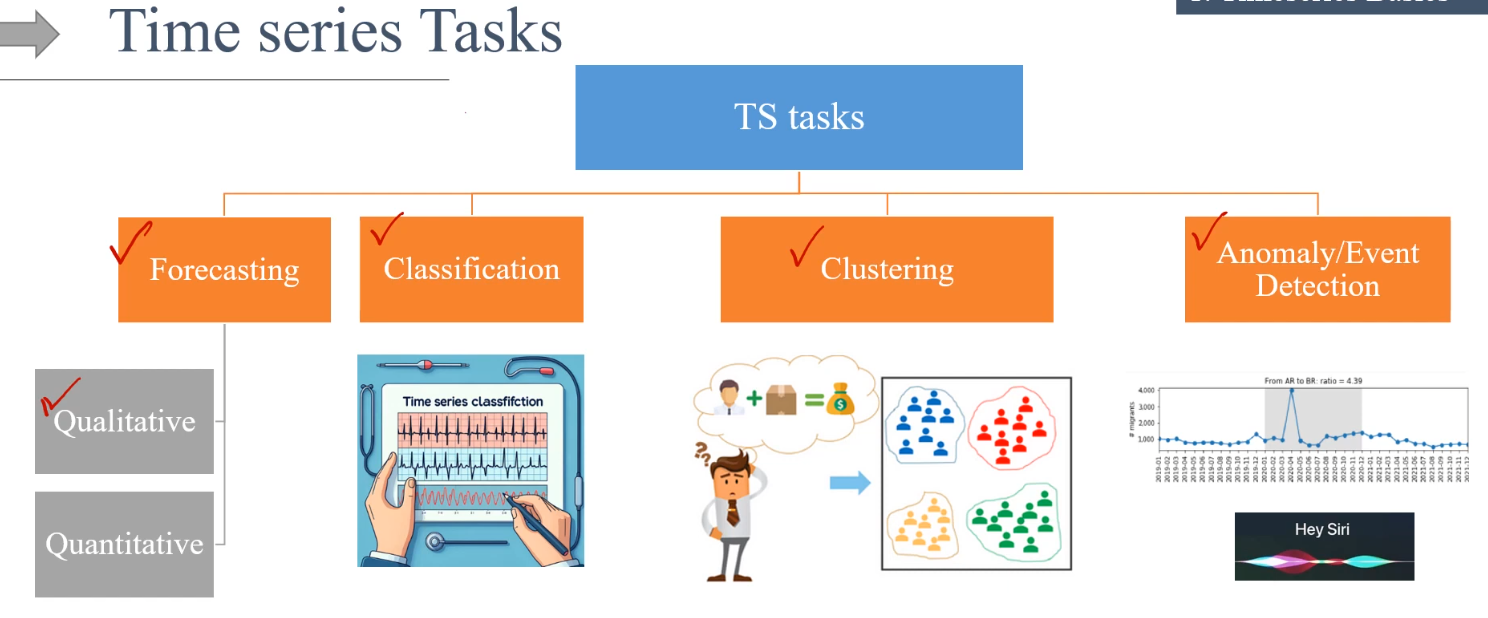
TS Tasks
I TS possono essere utilizzati per varie tipologie di task, es:
1) previsioni, che possono essere qualitative o quantitave
2) classificazioni
Le classisicazioni invece vengono utilizzate quando vogliamo assegnare delle "label" alle sequenze temporali. Un esempio potrebbe essere quello dello smartwatch che, sulla base della frequenza cardiaca classifica il tuo stato che potrebbe essere, in corsa, camminata, oppure a riposo. questa modalità è anche deta "supervised learnig")
3) clusterizzazioni
Le clusterizzazioni funzionano come le classificazioni ma senza le label, è il sistema che automaticamente ragruppa i dati sulla base di caratteristiche che identifica autonomamente. (questa modalità è anche deta "un-supervised learnig")
Un utilizzato nella classificazione dei clienti o per capire eventuali trend.
4) rilevazione di anonalie / eventi
Viene utilizzato per identificare dei comportamente fuori dal trend o inaspettati
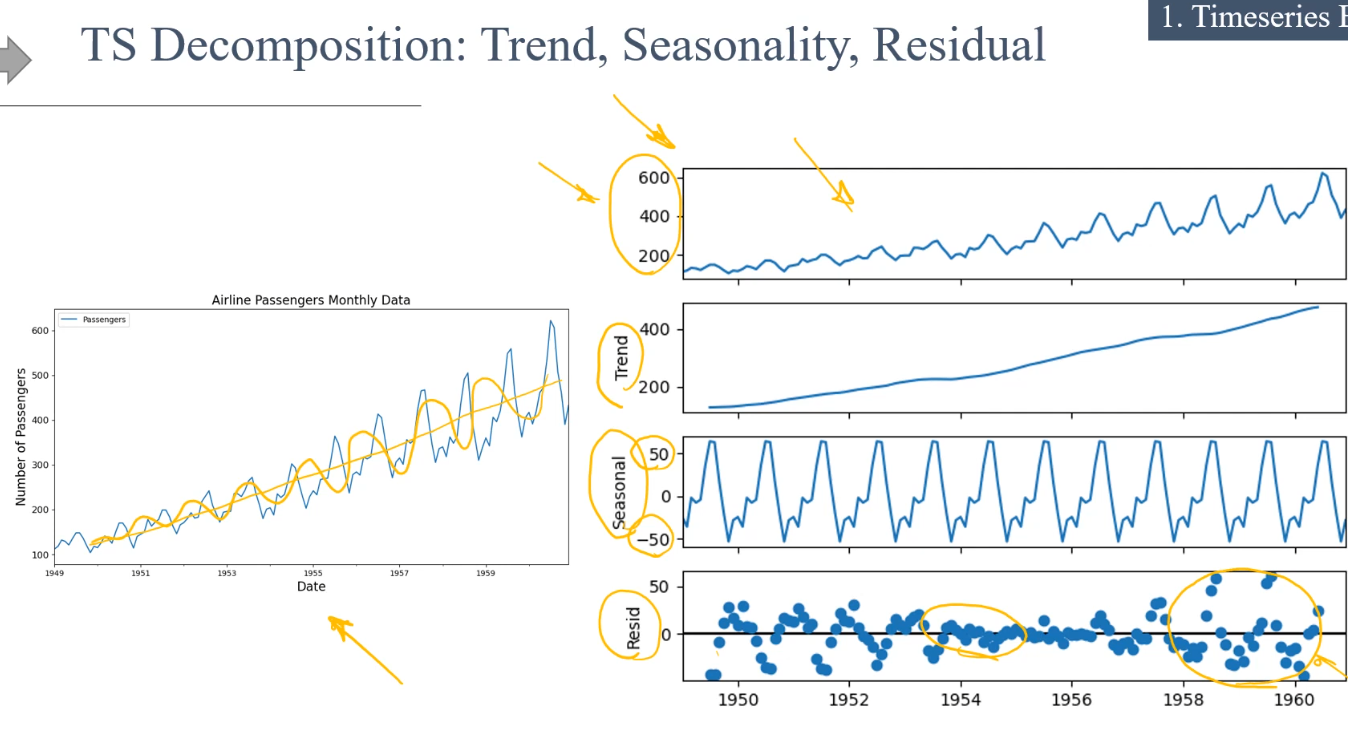
Scomposizione di una serie temporale
Un serie temporale piò essere scomposta in:
1) dati della serie
2) tendenze
3) stagionalità
4) dati residui
Per esempio nel grafico si vedono il numero di passaggeri nell'arco degli anni. Nel primo grafico a dx si vedono tutti dati "grezzi" in una scala da 0 a 600. Nel trend invece, gli stessi dati vengono "puliti" per mostrare un andamento con una scala diversa da quella dei dati grezzi. Invece nel terzo grafico a dx gli stessi dati grezzi vengono filtrati per stagionalità, anche qui notare come la scala cambia.
Nell'ultimo grafico vengono invece evidenziati i dati "residui" in pratica si tratta di "rumore" che in qualche modo vanno filtrati per rendere l'analisi più precisa.