Apprendimento supervisionato
Nel Supervised Learing (SL) vengono passati all'algoritmo gli input - detti anche “features”, e gli output corrispondenti agli input, detti anche “targets” o "labels".
L'algoritmo produce quindi una funzione (f) (f minuscola) , in input alla funzione vengono passate le features detta anche x (x minuscola) e ritorna le y^ (y cappello) che rappresentano i valori predetti dalla funzione.
NB La funzione f è detta anche “modello”.
La differenza tra y e y^ è che la y è il training set di features (quindi i valori noti da passare durante la fase di training) metre i valori y^ sono i valori stimati che il modello prevede in base agli input. (post fase di traing)
Regressione lineare
Tramite la regressione lineare univariata, viene determinato matematicamente l'output della funzione dato l'input, o se vogliamo dirla in altro modo, viene calcolata la Y in funzione della X. (tipicamente determinato la funzione che meglio fitta di valori X e Y)
La RL serve per determinare i valori della funzione che meglio soddisfano l'andamento di un fenomeno relativo ai valori appartenenti all'insieme delle fetures/labels (x,y)
La funzione si può rappresentare come y = b + wx dove b è “intercetta” (ovvero il delta y rispetto allo zero detto anche “bias” in inglese ) mentre la w è il “coefficiente angolare. (ovvero l'inclibazione della retta detto anche ”weight" in inglese o “slope” ovvero pendenza nel caso della funzione)
Nel Machine Learning (ML) i parametri “w” e “b” sono detti anche coefficienti o pesi.
Costo della funzione
La Cost Function (CF) nella pratica confronta il valore “predetto” y^ e il valore di training y, nella pratica è una differenza tra i due valori che definiamo come “errore”, ponendo il delta al quadrato, ovvero:
Sommatoria di (y^ - y)^2 per tutti i valori “m” del training set; diviso per “m” ovvero, viene ritornato la media degli errori -> questo si chiama “metodo dei minimi quadrati”
L'intento è quindi quello di trovare il valore minimo della funzione di costo.

Si tratta quindi di trovare la funzione che minimizza l'errore.
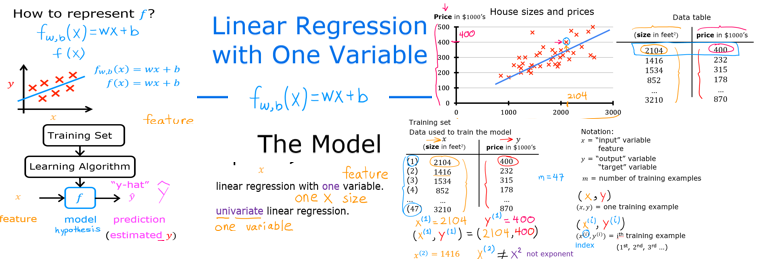
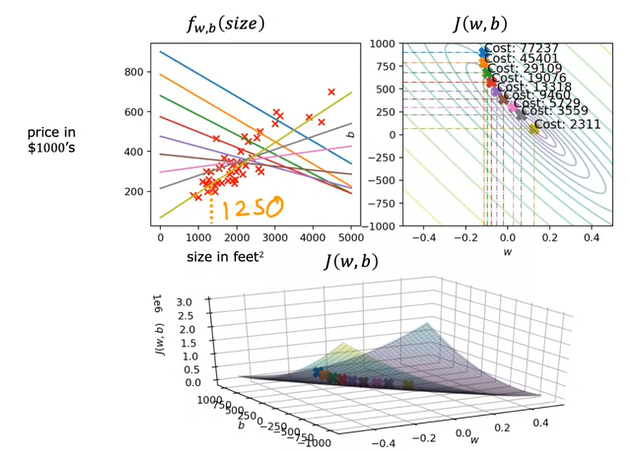
Nell'immagine sotto riportata a sx vengono visualizzate le funzioni ottenibili al variare del permarametro “w”
NB: per semplicità l'esempio pone b= 0 per rendere il grafico più facilemente interpretabile perchè in questo modo il gradico è 2D, se considerassimo anche
il valore b, allora il grafico sarebbe 3D e quindi un pò più difficile da leggere. (vedi es. grafico 3D riportato in pagina)
Si può notare che nella parte sx al varia della funzione si ottengono diversi valori J (ovvero errore) che, se rappresenti graficamente disegnano una curva
dove l'errore minimo si trova quando, per es. nel caso specifico, w vale 1. (grafico a DX)
Il grafico a DX disegna sulle ordinate (y) l'errore mentre sulle ascisse (x) il valore w ottenuti dall'applicazione del metodo
dei minimi quadrati. (vedi grafico a SX)
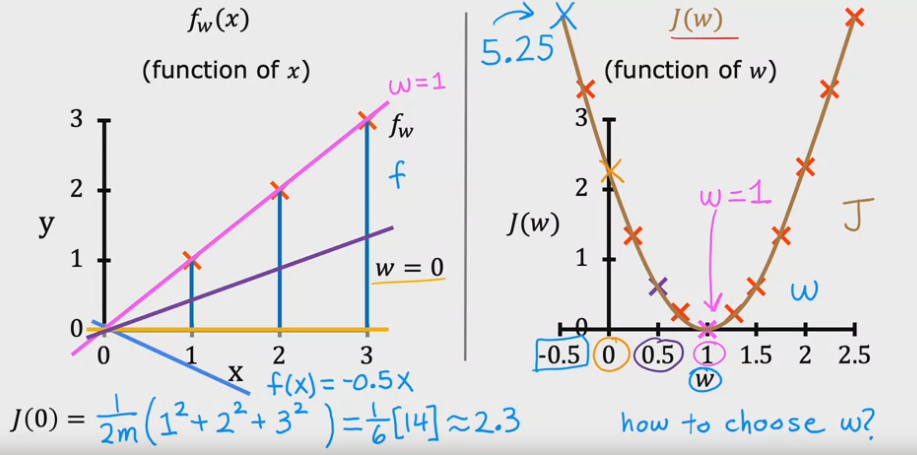
Nel caso in cui considerassimo anche il parametro “b", il grafico del cost function sarebbe renderezzito in 3D, come sotto rappresentato.
Considerazioni finali
Per determinare il “costo della funzione minimo” o l'errore minimo bisogna determinare i parametri “w” e “b” che avvicinano la funzione al set di dati.
Per determinare questi parametri in maniera algoritmica viene utilizzata la tecnica matematica denominata “gradiant descent” o “discesa del gradiente” analizzata nel paragrafo successivo.
Discesa del gradiente
La discesa del gradiente (GD) è un modo sistematico per determinare i parametri “w” e “b” in modo che minimizzino
il "costo della funzione" (l'errore della funzione)
Ricordo che stiamo parlando della funzione i cui coefficienti (w e b) contribuiscono a determinare
i valori che più si avvicinano al set di dati passati in input (features e labels)
Quindi J(w,b) -> costo della funzione (ovvero la sommatoria dei delta dati da labels - labels calcolate con i coifficienti w)
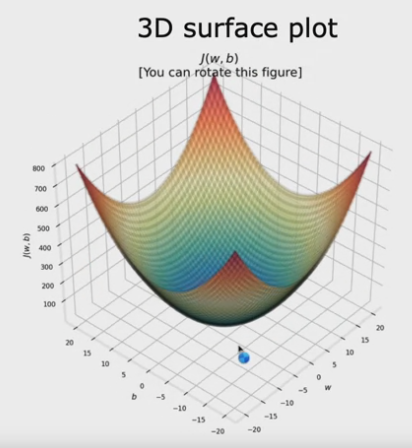
Tramite questo metodo si procede per “piccoli passi” al fine di trovarel l'errore minimo J(x,b), nota che
possono esistere più minimi (detti anche “minimi locali”) che dipendono dal valore di partenza che in genere è randomico.

Nella pratica si tratta di looppare i valori “w” e "b" calcolati ad ogni iterazione del ciclo. (vedi immagine sopra)
Il valore di w è quindi settato a = “w” meno un parametro “alpha” (detto anche learning rate, valore piccolo compreso tra 0 e 1, es. 0,001) moltiplicato
per la derivata del costo della funzione J(w,b).
Stessa cosa per il parametro b.
Il valore di “learing rate” (LR) è indica la grandezza del “passo”, ovvero la velocità con la quale saliamo i discendiamo il grafico
del costo della funzione.
Attenzione che andare veloce può causare un “salto” eccessivo e farci perdere il punto di minimo.
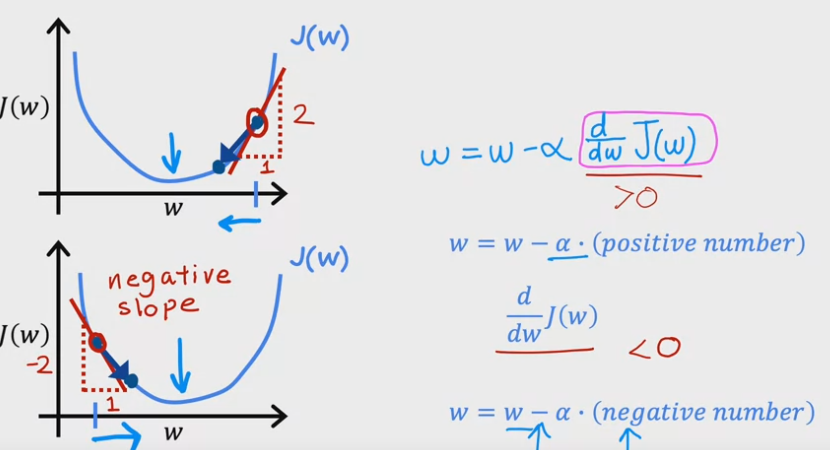
Sopra viene indicato il calcolo della derivata parziale rispetto al valore “w”. Vengono rappresentati due casi, il primo
dove viene preso a caso un valore “w” a DX dal minimo; In questo caso la derivata parziele ritornerà un numero positivo
in quanto, la derivata indica l'inclinazione della tangente passante per il punto scelto sulla curva avente per coordinate (w1,j(w1))
e in questo caso indica che la tangente è ascendente.
La derivata del costo della funzone indica se la funzione è a un minimo (anche locale) oppure se si trova in discesa o in salita. In pratica
restituisce la pendenza (o la direzione) del punto tangente alla funzione di costo nelle coordinate indicate.
Ora il nuovo “w” viene calcolato sotrraendo il " LR x lla derivata" al valore “w” , essendo positivo, diminuirà il valore finare di “w”.
Stessa cosa, ma invertita di segno in quanto il valore di w preso a SX del minimo è discendete. Quindi, il valore della derivato
del costo della funzione viene negato in quanto la formula sottrae sempre il valore della derivta parziale del costo di “w” e di “b”.
Idem per la variabile “b” fino a quando i valori convergono intorno al minimo della funzione.
Learning rate
Il valore di “learning rate” (LR) nella pratica serve per fare “lo step” nella direzione del minimo in cui valore è dato dal vosto della funzione.
LR però non può essere un valore troppo piccolo in quanto rallenterebbe in maniera importante la determinazione del minimo e, non può
essere nemmeno troppo grande in quanto rischia di far saltare il punto di minimo, sia esso locale che globale.
Per questo motivo il modo migliore per settare il parametro alpha (detto anche LR) è gestire dinamicamente il valore da algoritmo in modo
che sia un valore relativamente grande se la pendenza (slope) dato dalla derivata nel punto della funzione di costo è elevato, piccolo se lo
slope tende allo zero in quanto significa che siamo prossimi al minimo.
Di seguito viene mostrato il calcolo delle deritavate parziali rispetto a “w” e rispetto a “b" per determinare il minumo del costo della funzione.
NOTA di calcolo, si tratta di applicare il teorema della derivata della funzione composta (detta anche "chain rule) rispetto a w e rispetto a b ovvero:

che applicando il tutto alla funzione di costo si ottiene:

Quindi l'algoritmo di calcolo della discesa del gradiente si calcola come:

Conclusione
In conclusione, la regressione lineare consente di determinare il valore minimo relativo al costo della funzione.
Il costo della funzione ritorna la sommatoria degli scostamenti tra la funzione (ad una o più variabili) e l'insieme dei valori (campioni)
labels-features al variare dei coefficiente “w” e “b”.
Al variare di questi coefficienti si genera un insieme di valori dove ciascun valore è un totale che se rappresentato
graficamente, disegna un grafico in 2D (se varia solo un valore) in 3D se variano sia “w” che “b”, del quale dobbiamo trovare
il minimo per identificare la funzione che minimizza l'errore.
Per trovare l'errore minimo si utilizza il metodo della discesa del gradiende, che consente tramite l'utilizzo delle derivate parziali
nel punto iesimo, di avvicinarsi progressivamente al “minimo locale” oppure al “minimo assoluto” avanzando tramite un passo definito “learing rate”.
Di seguito un esempio di come al variare dell'intercetta e del coefficiente angolare, andando con passo (LR) la funzione
giunge al suo costo minimo.
Regressione lineare multipla
PREMESSA:
f(w,b) = modello
J(wb) = costo della funzione -> f (w,b) - y -> dove y sono le label
DISCESA DEL GRADIENTE = d/dw J(w,b) in sistema con d/db J(wb)
Nella regressione lineare univariata (RLS) abbiamo solo una "feature" e una corrispettiva “label”, per es. metri di un appartemento e corrispettivo prezzo.
Nel caso della regressione lineare multipla (RLM) invece, abbiamo più features a fronte di una label, per es. oltre ai metri quadrati dell'appartemento
abbiamo anche il numero di stanze, l'età dell'immobile, piano, etc etc e ovviamente come label il prezzo.
NB: la RLM non è la regressione lineare multivariata, che non conosco.
Il modello che era stato definito per la regressione lineare singola si basa sulla funzione f(x) = wx + b che in pratica definisce la funzione
(attraverso l'opportuno settaggio dei paramerti w e b tramite la discesa del gradiente) che meglio si accosta alle features/label definite per il training.
Nel caso invece della RLM, la formula diventa un polinomio del tipo (consideranto 4 features) f(x) = w1x1 + w2x2 + w3x3 + w4x4 + b
Dove x1,2,3,4 sono le features, mentre w1,2,3,4 sono i coeffienti angolari tutti potenzialmente diversi.
es:
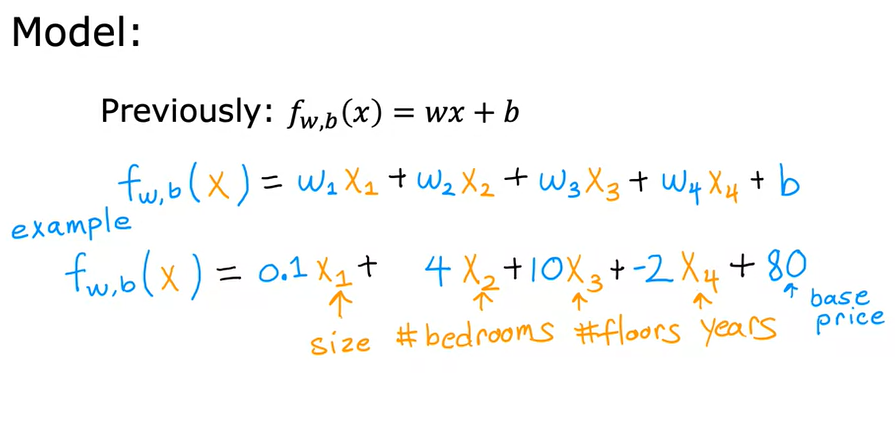
che si può rappresentare anche:
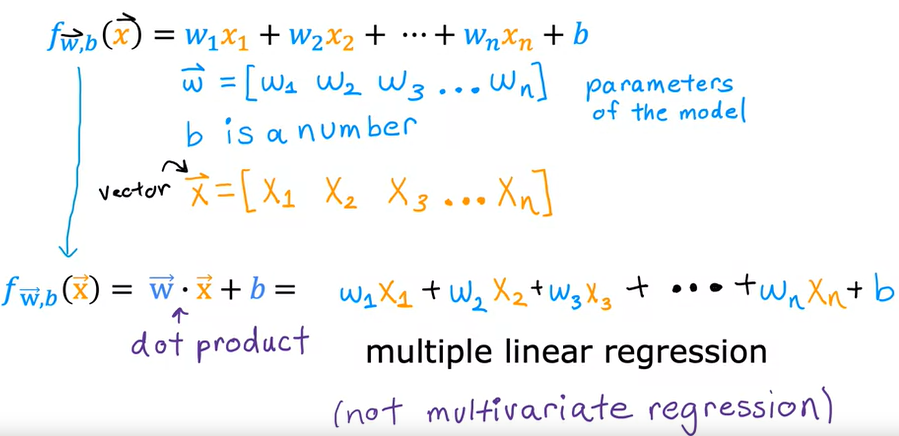
Per risolvare questa equazione viene utilizzato il metodo della Vettorizzazione. (Vectorization)
La Vettorizzazione consente nella pratica di efettuare la moltiplicazione tra vettori/matrici utilizzando la libria numpy che sfrutta appino l'hardware della macchina.
Discesa del gradiente
Il GD a più variabili è simile a quello univariato con la differenza che al posto di un solo “w” e una sola “b” c'è un vettore di w
Il calcolo è simile se non per il fatto che bisogna iterare per il numero di features
Nella pratica la regressione lineare multipla si calcola in 2 marco step:
0) date le features e le labels di esempio:
X_train = np.array([[2104, 5, 1, 45],
[1416, 3, 2, 40],
[852, 2, 1, 35]])
matrice di 3 righe di traing con 4 colonne di features per ogni riga
e
y_train = np.array([460, 232, 178])
una riga di labels
e
dati dei valorei a caso di “w” e “b”
b_init = 785.1811367994083
w_init = np.array([ 0.39133535, 18.75376741, -53.36032453, -26.42131618])
1) calcolo della funzione di costo su variabili multiple, come sotto riportato
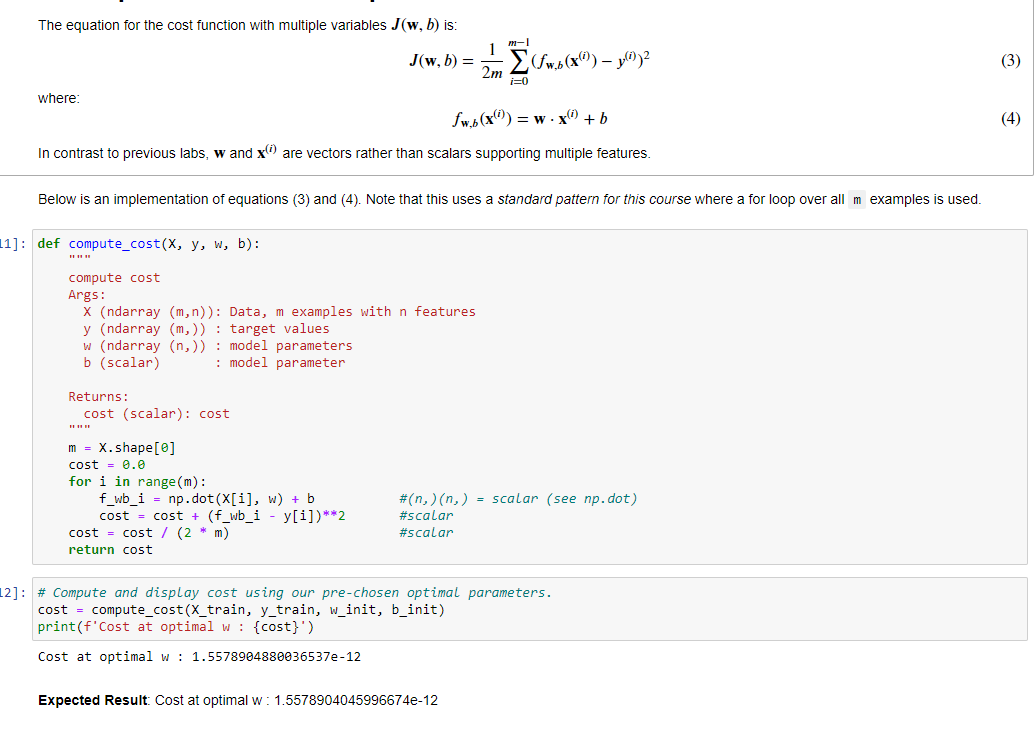
Il metodo “compute_cost” serve per calcolare il costo della funzione per i valore w e b passati per una SOLA iterazione.
Sarà poi la fase successiva a variare i w e b richiamando poi la funzione di costo per determinare il costo totale per poi ritare “w” e “b” di conseguenza
2) Calcolo della discesa del gradiente con variabili multiple
applicando la derivata del “calcolo della funzione di costo” loopando fino a che i valore “w” e “b” minimizzano il costo
NB: ricordo che si applica il metodo della "derivata della funzione composta" accennato nella sezione “GRADENT DESCENT” relativa al paragrafo
della regressione lineare univariate.

Nella pratica il calcolo delle derivate parziali in “w” e “b” si traduce in:

che viene richiamata in un loop di N iterazioni, ovvero:
In conclusione questo è la discesa del gradiente, purtroppo i risultati ottenuti non sono particolarmente brillanti, dopo
verrà illustrato come migliorare l'algoritmo.
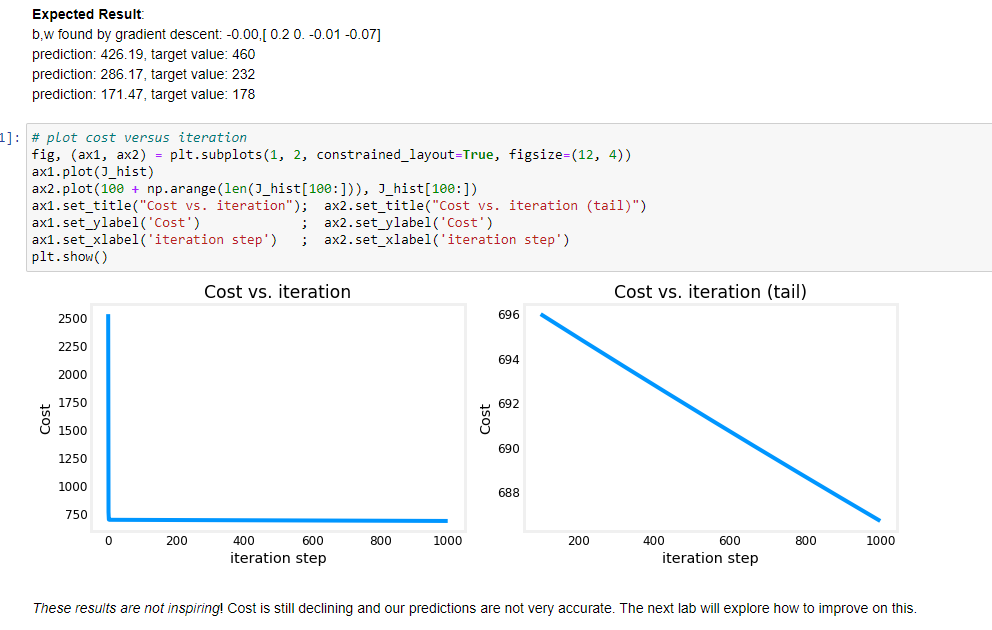
Scaling delle features e dei parametri
Nel caso in cui ci siano più features (come nella regressione lineare multipla) è importante scalare i valori delle diverse tipologie di parametri in input.
Es. se abbiamo due features come i metri quadrati e il numero di stanze di un appartmento, è bene riportare entrambi gli insiemi di valori
in un range compreso tra -1 e 1.
Il motivo è dettato dal fatto che in questo modo la regressione lineare trova più facilmente (velocemente) il suo minimo.
(vedi i grafici sotto riportati che indicano il minimo dei costi nella parte SX)
SCALING:
Le features e le label vanno quindi “normalizzati” scalandoli principalmente in questi modi:
1) dividere tutti i valori per il massimo
2) “centrando” i valori intorno allo zero applicando la formula (valori-valore medio)/(valore max - valore min)
di seguito un esempio:

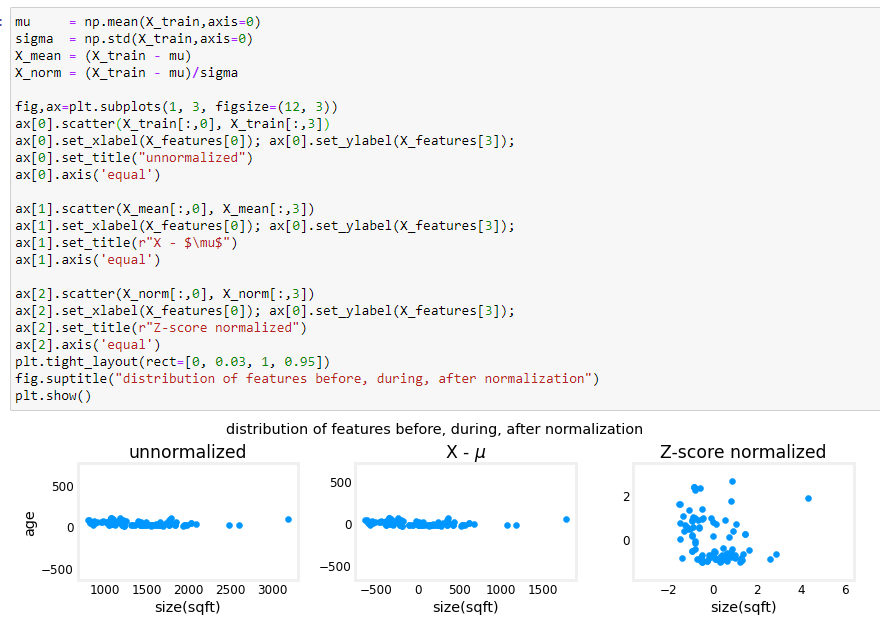
un metodo ottimale per normalizzare i dati è detto Z-SCORE che riporto di seguito:
Z-SCORE
Questo metodo nella pratica va a “centrare” le features e le labels inforno allo zero. In questo modo il calcolo della regressione
lineare risulterà più veloce e più accurato nella ricerca del valore minimo relativo al costo della funzione.
DEVIAZIONE STANDARD (o scarto quadratico medio)
La DS rappresenza rappresenta la distanza dei valori di una serie rispetto alla media e si calcaola come:
1) calcolare la media dei valori -> media semplice
2) calcare la varianza dei valori -> è la differenza tra il singolo valore e la media al quadrato il tutto diveso per il totale dei campioni
3) calcolare la daviazione -> è la radice quadrata della varianza

implementazione dell'algoritmo di ZScore
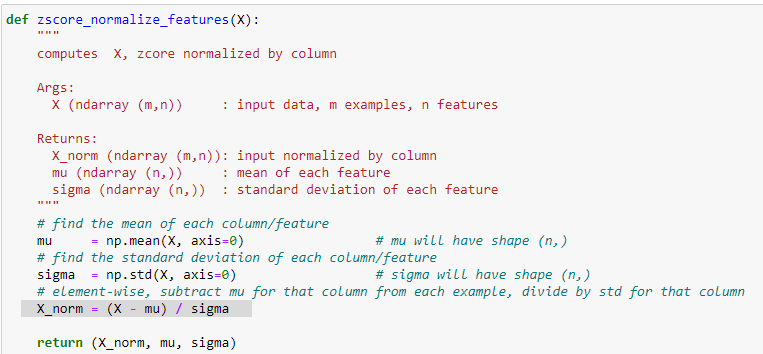
il cui output nell'esempio:
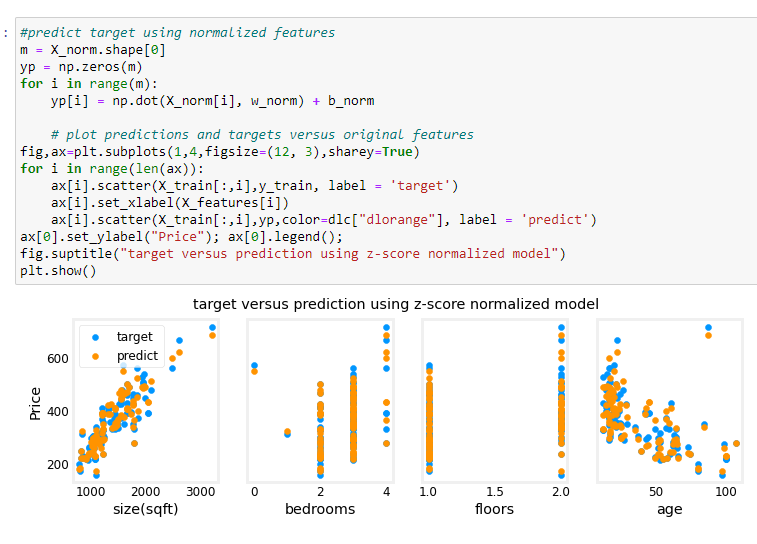
e adesso proviamo a predirre i valori.
Regressione polinomiale
Nella regressione lineare polinomiale la funzone di costo ragione per curve e non per linee rette come
invece accade della regressione lineare (singola o multipla)
Per ottenere questo risultato vengono utilizzate dei confficienti quadrati o cububici o valori esponenziali > di 3.
oppure utilizzare, al contrario, la radice quadrata della feature.
es:
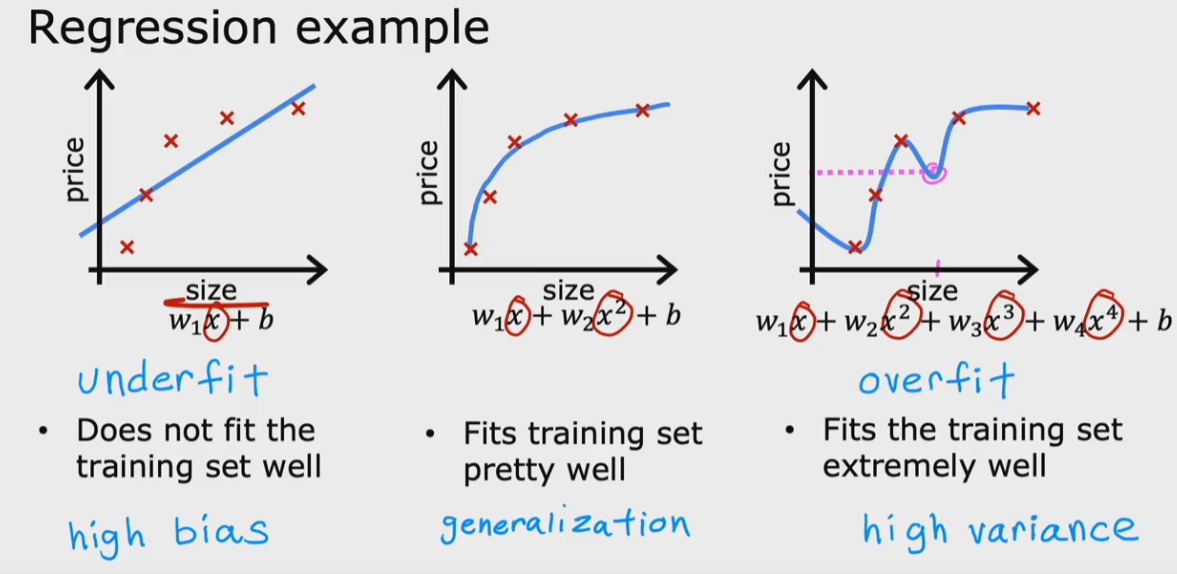
che poi viene dettaglio nel capitolo relativo all'overfitting/underfitting