Lezione https://www.youtube.com/watch?v=o9Rc1pCYaHo&list=PLMee1hSjLKdAL16E-7EzqHXsGOgzo8iro&index=23
##### Cosa significa aleatorio? (sinonimo di casuale o stocastico) E' un osservazione di un fenomeno il cui risultato non è determinabile a priori. (es. le previsioni del tempo, o il valore di un titolo azionario, o il lancio di un dado) Pur non essendo l'esito sicuro dell'informazione si può comunque estrapolare, per es. nel lancio del classico dado otterremo un valore intero da 1 a 6 non 3,8 in virtù della tipologia del fenomeno. La descrizione matematica che permette di affrontare questa tipologia di problemi si chiama probabilità. ##### Spazio campionario Nell'ambito di un esperimento questo "**spazio campionario**", rappresntato dal simbolo Ω (omega), contiene tutti gli esiti possibili dell'evento che stiamo esaminando. Es. evento lancio di un dado, lo spazio compionario conterrà tutti gli esiti possibili del lancio del dato, quindi l'insime dei numeri possibili da 1 a 6. -> Ω = {1,2,3,4,5,6) Non sempre però lo spazio campionario è un numero finito, es. il numero di accessi ad un sito web, in questo caso è l'insieme di tutti i numeri naturali, es. Ω = N0 (dove N0 è l'insieme dei numeri naturali) Se il numero non è discreto nel caso in cui la misurazione è contina allora l'intervallo è omega comprende tutti i valori da zero a infinito, ovvero: Ω = \[0, +∞) Quindi esistono tre tiologie di spazi campionari: 1. discreto finito 2. discreto inifinito 3. continuo ##### Modello probabilistico Rappresenta la probabilità (o fiducia) che si verifichino i valori dello spazio campionario. Es. quale è la probabilità che il numero ottenuto con il dado sia pari. (2,4,6) o la probabilità che il numero di accessi al sito web sia minore di 100. Il RL si occupa dello spazio campionario finito. (caso 1) ****Definizione****: la probabilità su tutto lo spazio campionario è sempre 1. (es, quale è la probabilità che lanciando un dado esca 1 o 2 o 3 o 4 o 5 o 6 ? è il 100% ovvero 1) P(Ω) = 1. Invece la probabilità dell'insieme vuoto è zero. ****Definizione****: I sottoinsimi dello spazio campionario sono detti eventi. es. nel dato il sottoinsieme (evento) 1 potrebbe essere P {1,2} un altro sottoinsieme potrebbe essere P{3,4,5) e così via. Vien da se che Ω contiene tutti gli eventi possibili, NB: tutto questo vale quando gli eventi (sottoinsiemi) sono disgiunti, ovvero non si intersecano). Suggerimento, pensiamo alla probabilità di un insieme come all'area di un cerchio, nel caso di insiemi disgiunti la probabilità dei due sottoinsiemi è semplicemente la somma, se invece i due sottoinsiemi si intersecano allora è la somma delle due probabilità meno la probabilità della loro intersezione. ##### Densità uniforme Data una probabilità P su uno spazio finito e numerabile Ω, possiamo associare a P una funzione p detta ****densità****, definita su omega valori \[0,1\]. Quindi la densità è definita SOLO sugli elementi di omega. La probabilità dell'insieme che contiene il singolo elemento è funzione del singolo elemento. es. nel lancio del dadi la probabilità dell'insieme P({1,2,3}) è la somma delle probabilità dei singoli elementi che indicheremo con p minuscola ovvero: P({1,2,3})= p{(1)} +p{(2) }+ p{(3)} ATTENZIONE: con P maiuscola ci indica la probabilità mentre con la p minuscola si indica la funzione che resituisce la probabilità. Per es. la densità definita sullo spazio campionario del lancio del dado, P: {Ω} -> \[0,1\] mentre la densità di ogni elemento di Ω è p(1) = 1/6... fino a p(6)= 1/6 Altro esempio ##### Esperimento Bernulliano un esperimento bernulliano è una variabile che può indicare successo o non successo, è una varibile booleana. La variabile che indica la proabilità di successo è P mentre quella che indica l'insuccesso è (1-P), insieme omega è quindi Ω = {successo, insuccesso} o Ω = {1,0} Esempio: qual'è la probabilità di ottenere un successo alla K-esima volta che facciamo un esperimento. (es. alla 10a volta) ciò significa che per i primi 9 lanci non deve verificarsi il successo (1-P) e al decimo deve valere P. Per i primi 9 lanci le probabiltià si devono moltiplicare (1-P)\*(1-P)\*(1-P)\*(1-P)\*(1-P)\*(1-P)\*(1-P)\*(1-P)\*(1-P)\*P = exp((1-P),K-1)\*P ##### Densità non uniforme a preferenze (SoftMax) Esistono casi in cui gli elementi dello spazio capionario hanno delle **preferenze** (o dei **pesi**) che ne alternano in qualche modo le probabilità. **NB**: L'intento è quello di trasformare queste preferenze (o pesi) in probabilità. Però ci sono dei pesi negativi. Nel caso in cui questi "pesi" abbiano valori negativi, come si calcola il peso in termini probabiliststici di ciascuno elemento di omega rispetto agli altri? Il caso viene illustrato nell'immagine sotto riportata dove vediamo ciascuno preferenza H definita per ciascuna delle 6 facce delle dado. Si può notare che esistono delle preferenze negative che se dovessimo calcolare semplicemente come peso della singola preferenza fratto sommatoria di tutti i pesi, ne risulterebbe una probabilità negativa. Quindi per es. se volessimo calcolare la probabilità di P(H1) sarebbe -> 100 / (somma di tutti i pesi) . Però non funzionerebbe in quanto abbiamo dei pesi negativi, e nel caso per es. di P(H3) verrebbe una probabilità negativa, il che sarebbe sbagliato. [](https://cms.marcocucchi.it/uploads/images/gallery/2024-10/6QjP8ghzfqi3wsEW-image.png)Per nornalizzare questi valori si applica semplicemente la **funzione esponenete** per ciascuna preferenza che rende tutti i numeri > 0. (anche con esponente negativo i valori sono sempre > 0) quindi diventa. (non considerare la variabile beta)
Q quindi diventa: [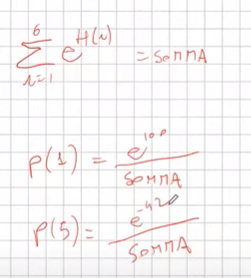](https://cms.marcocucchi.it/uploads/images/gallery/2024-12/YZARPvPEoiaXEPFM-image.png) Questa tecnica per normalizzare i pesi è detta **softmax**. E' importante perchè la somma delle probabilità di tutti i valori "pesati" da 1. Nel caso di insiemi discreti non finiti si applicata la formula Poisson. (che in questo momento non ci interessa) ##### Contare le combinazioni di eventi complessi Supponiamo di poter filtrare un insieme per determinare caratteristiche che si sommano in successione. Utilizziamo degli esempi: 1\) voglio determinare le carte pari di cuori e picche da un mazzo di carte di poker: Applico la regola delle caratteristiche che si sommano, In questo abbiamo 2 caratteristiche, ovvero: caratteristica 1) le carte pari ->5 su 13 caratteristica 2) i semi di carte -> 2 su 4 quindi sommiamo la caratteristica 1 e 2 che matematicamente significa moltiplicare, ovvero: 5\*2 = 10 2\) sempre la mazzo di poker voglio trovare tutte le combinazioni di full possibili. (3 carte dello stesso valore + 2 dello stesso, esclusi vicendevolmente es. 3 carte di assi + 2 carte di jack) In questo abbiamo 4 caratteristiche, ovvero: caratteristica 1) 3 carte uguali -> 13 caratteristica 2) 2 carte uguali (in quanto vado ad escludere il tris) -> 12 (in quanto non possono esistere 5 carte con lo stesso valore) caratteristica 3) 3 carte che hanno 3 semi su 4 -> 4 presi in combinazione di 3 (combinazioni semplici senza dipetizione C(4,3) caratteristica 4) 2 carte che hanno 2 semi su 4-> 4 presi in combinazione semplice senza ripetizione C(4,2) = 13\*C(4,3)\*12\*C(4,2) = 3744 #### Calcolo combinatorio Di seguito un breve ripasso del calcolo combinatorio ##### Disposizioni semplici Le disposizioni prese da un insieme di N elementi in K modi (es. da un insieme di 10 numeri (N) presi a 2 (K) ) sono un sottoinsieme di numeri ordinati, dove l'ordine del numero **conta**, allora la formula diventa N! / ( N-K)! ##### Combinazioni Se invece l'ordine dei **non** conta allora il numero di casi dimunuisce quindi la formula diventa N! / K! \* (N-K)! ##### Probabilità condizionata **Premessa**: l'informazione cambia le probabilità. *Premessa bis*: La proababilità ovviamente si calcola come casi favorevoli fratto casi possibili. *Es*, qual'è la probabilità che lanciando un dado esca il numero sei? ovviamente 1/6. Supponiamo invece che dopo aver lanciato il dado qualcuno ci dica che è uscito un numero pari, ora come cambia la probabilità? in questo caso lo spazio campionario (omega) cambia e passa da sei numeri a tre tutti pari, a questo punto la proabilità diventa 1/3. Sia un evento A condizionato a B -> P (A **|** B) il calcolo diventa P(A|B) = **P(A ∩ B) / P (B)** ##### Indipendenza di eventi Premessa: In genere sapere il verificarsi di un certo evento ci da informazioni sulla probabibilità di un altro evento. Ci sono però casi che l'informazione non modifica che la probabilità che modifichi l'evento. Quindi P(A|B) = P(A) significa che se la probabilità di A condizionata all'evento B è invariata allora i due eventi sono indipendenti. L'intersezione dei due eventi rende la probabilità una funzione moltiplicazione, ovvero: **P(A ∩ B) = P(A) \* P(B)** # Sessione 1 Nell'apprendimento per rinforzo (d'ora in poi verrà indicato con RL) si basa sul **processo decisionale di Markov** aka MDP attrraverso un task di controllo dove un set di possibili stati e azioni ritornano un reward e una probabilità di passaggio ad uno stato all'altro. Il task nella pratica è un "compito" o una simulazione che per essere svolta (risolta) implica l'utilizzo dell'MDP. **NB**: Il processo decisionale di Markov (MDP) asserisce che il passaggio allo stato successivo T+1, dipende esclusivamente dallo stato attuale T e non dagli stati precedenti. Quindi il processo **NON** ha memoria, in questo caso si dice che il processo è "Markoviano". ##### Tipologie di processi decisionali di Markov (MDP) Esistono due tipologie di MPD, il processo a stati finiti e quello a stati infiniti. Nel MDP finiti gli stati finiti hanno un numero finiti di stati definiti dall'ambiente, es. l'uscita da un labirinto di 5 caselle x 5. In questo caso abbiamo 25 stati e 4 azioni (su, giù, dx e sx) Nel MDP a stati infiniti, invece, l'ambiente appunto può restituire infiniti stati a fronte di infinite azioni, pensiamo per es. il sistema di guida automatica di una macchina dove l'azione es. girare il volante, è un valore continuo così come la scelta della velocità dell'auto. ##### Episodi MDP definisce anche degli "episodi" in particolare: Nel MDP episodico un episodio termina a determinate condizioni. Es. nel gioco degli scacchi quando la giocare da scacco matto. Nel MDP continuo, il processo non ha fine, semplicemente continua ad esistere all'infinito in quanto non esiste uno stato fine. ##### Traiettoria ed episodio La traiettoria è il movimento che l'agente compie per muoversi da uno stato all'altro. La traiettoria è definita dal simbolo greco 𝜏 "tau". Un esempio può essere: 𝜏 = S0, A0, R1, S1,.A1, R2, S2, A2, R3, S3 che indica la partenza dallo stato zero, dove viene effettuata l'azione A0 che porta la reward R1 e il posizionamento nello stato S1, alla quale segue l'azione A1 e così via. L'ultimo stato della traiettoria sarà (nel caso specifico) S3. La *treittoria* può essere finita o infinita, se è finita si chiama episodio è semplicemente una traiettoria che inizia in uno stato e finisce nello stato finale oltre quale non si torna indietro. es: = S0, A0, R1, S1,.A1, R2, S2, A2, R3, S3, ..... **RT,ST**. [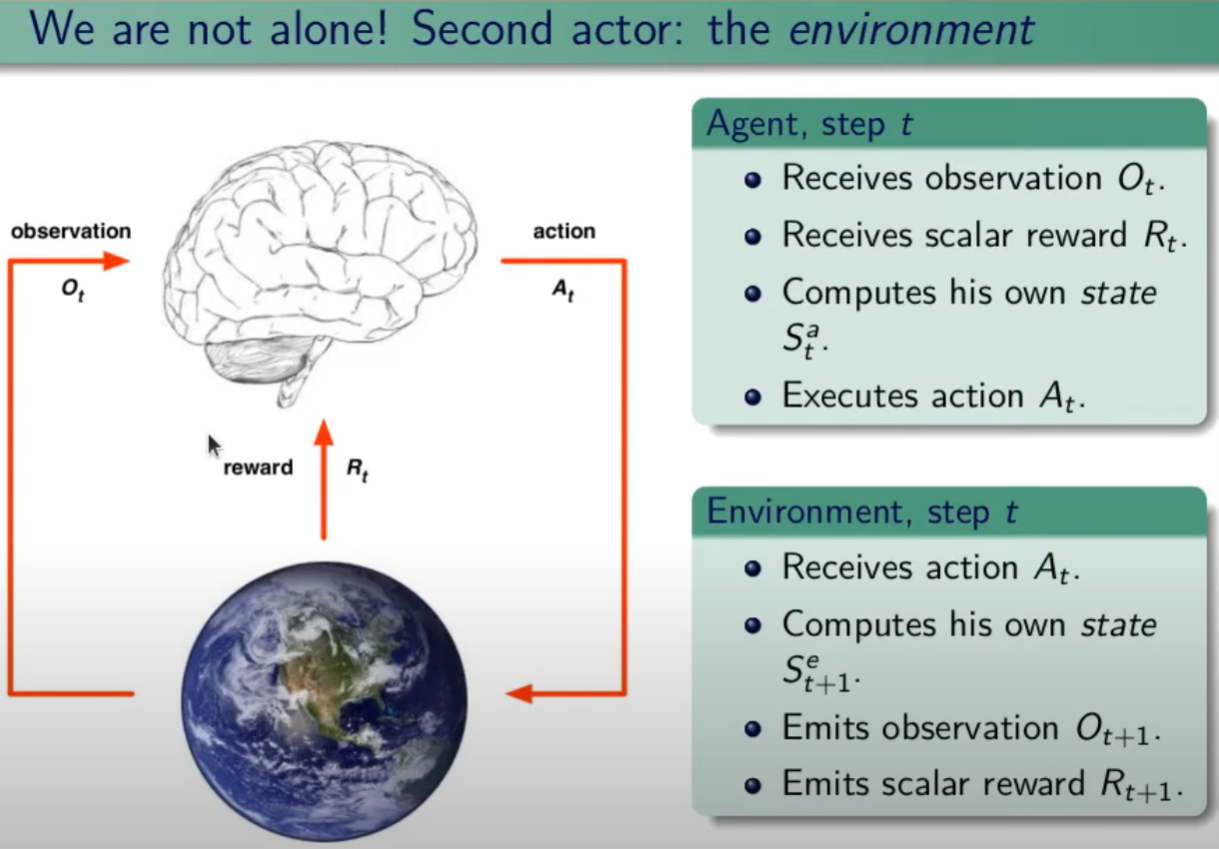](https://cms.marcocucchi.it/uploads/images/gallery/2023-06/MacBQFXk2qoHPQ9O-screenshot-2023-06-25-090815.png) di cui deriva il concetto di storia, ovvero la somatoria delle osservazioni, ricompense e azioni fino all'azione finale. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-06/tbRyUHL29ohkSngz-screenshot-2023-06-25-091029.png) ##### Ricompensa vs Ritorno La **ricompensa** (*reward*) viene restituita a fronte di un'azione, quindi per risolvere un task, dobbiamo massimizzare le ricompense ottenute. La ricompensa è quindi un risultato **immediato**. (Rt) Invece il **ritorno** è la somma di tutte le ricompense ad un determinato momento nel tempo es: **G(t) **= R(t+1) + R(t+2) + ... R(T) finchè il task è stato completato. ##### Predizione, miglioramento e Controllo La *predizione* significa calcolore il valore di una certa policy fissata, il *miglioramento*, come dice la parola serve per migliorare (anche solo di poco, non la miglioare in assoluto) la policy attuale, mentre il *controllo* serve per trovare la migliore di tutte. Da qui il ciclo utile per trovare la policy migliore: pi(s) -> Vpi(s) -> pi'>= pi che inserire in un loop fino a quando converge. (teorema banach caccioppoli) ##### Fattore di sconto **γ** (gamma) Il fattore di sconto è un incentivo per completare l'episodio nel miglior modo (più efficiente) possibile. Per ottenere questo la ricompensa dovrà essere moltiplicata per il fattore di sconto che diminuirà nel tempo all'aumentare delle azioni intraprese, rendendo le ricompense sempre più basse e quindi disincentivando le traiettorie lunghe. Il fattore è un valore compreso tra zero e uno e viene elevato ad un esponente corrispondente dall'iesima azione fino alla fine dell'episodio. Se **γ** *(*gamma) vale zero l'agente cercherà di prendere una ricompensa immediata, il che denota una strategia miope che non ottimizza l'apprendimento. Al contrario invece, un fattore **γ** gamma pari a uno, rende l'agente più "paziente" e quindi non prono ad ottimizzare gli step dell'episodio. In genere il fattore gamma viene settato a 0,99 che forza l'agente ad avere una ricompensa immediata ma allo stesso tempo lo forza ad avere una visione "a lungo termine". In conclusione il fattore gamma indica all'agente quanto può valutare in maniera ottimali le azioni future. **NB**: se il task è *episodico* allora è possibile utilizzare un fattore di sconto pari a 1, diversamente se il task è *continuo* (infinito senza stati assorbenti terminali) allora il tasso di sconto è meglio che sia <1. ##### Policy La policy dell'agente è una funzione che prende in input uno stato e ritorna l'azione che va presa in quello stato. E' rappresenta dalla lettere greca pigreco **π** [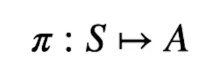](https://cms.marcocucchi.it/uploads/images/gallery/2022-11/861YiH69FKsiyAIg-screenshot-2022-11-28-222728.png) La probabilità di eseguire un'azione (a) nello stato (s) si può rappresentare come:π(a|s) L'azione che la policy sceglie nello stato (s) viene descritta dalla formula: π(s) Dipende quindi dal contesto, in alcuni casi si uitilzza il primo π(a|S) in altri il secondo π(s). La policy può essere di due tipi: **stocastica **o **deterministica**. Si dice che la policy è deterministica quando viene scelta sempre la stessa azione in un determinato stato quindi stiamo parlando del caso π(S). Si dice invece stocastica quando l'azione viene scelta sulla base delle probabilità es. : π(S) = \[0.3, 0.2, 0.5\] ovvero la probabilità di effettuare una azione nello stato S, è del 30% nel primo caso, 20% nel secondo e 50% nel terzo. Quindi siamo in presenza del caso π (a|S) Quindi bisogna trovare la policy ottimale rappresentata come π\* (pigreco - asterisco) che sceglie le azioni che massimizzano la somma dei fattori di sconto per le ricompense alla lunga. La policy π è una distribuzione di probabilità che deciamo noi dato lo stato con la quale scegliamo le azioni e prendendo quindi una decisione, si differenzia dalla probabilità che NON decidiamo noi che si rappresenta con **P** che invece rappresenta il modello la cui prabobilità non possiamo modificare. (es. P(s',r|s,a) )Il valore della policy V in genere indica la ricompensa totale media che si ottiene applicando la policy
##### Controllo Ottimale Nel RL è fondamentale determinare la Policy Ottimale π\* *indispensabile per la gestione dell'ambiente. La griglia di centro (visibile in figura) è la rappresentazione del valore di ciascuno stato. (dove per stato si intende ogni casella della griglia) Per valore ottimale* V\* si intende il valore della policy ottimale, ovvero quello che si può ottenere facendo le azioni migliori possibili. Per migliore azione si intende determinare lo scopo, ovvero massimizzare le somma delle ricompense (dette *ritorno*) ottenibili con le azioni future. La policy ottimale quindi, si ottiene valutando di volta in volta il valore ottimale. Le policy ottimali sono tante, anche su un unico stato, vedi per es. che nella casella in fondo a sx il cui valore è 14,4 ha due policy ottimali in quanto i valori ottimali in questo specifico caso sono due. [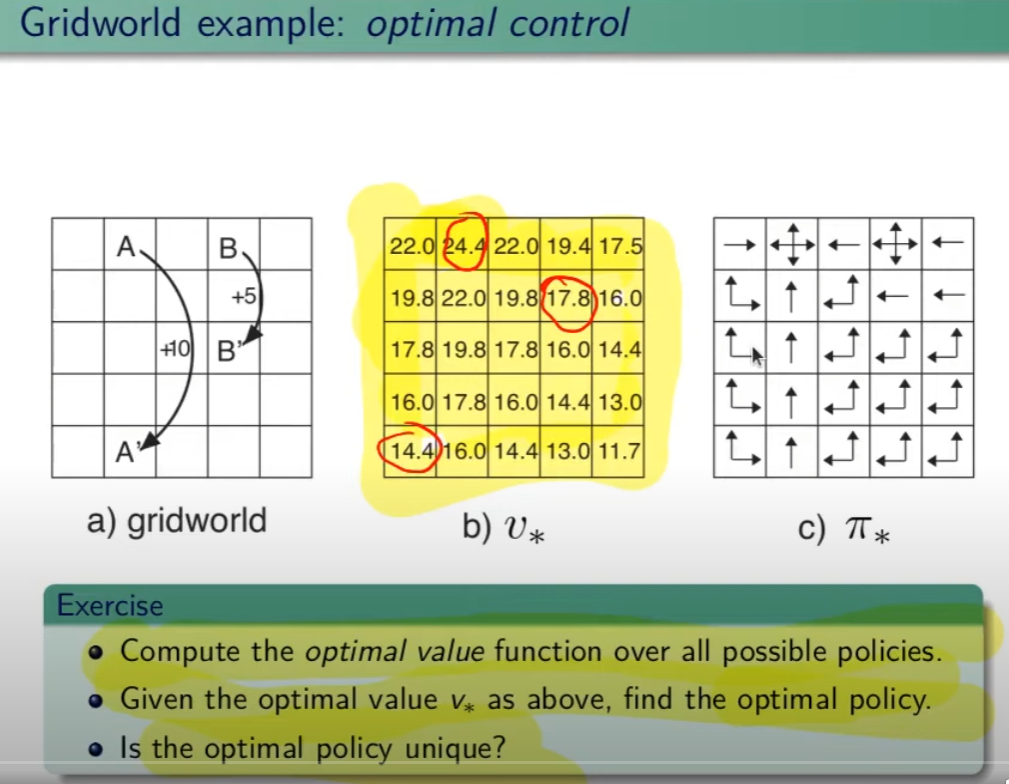](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/jEX4kRIuCJNCHQVh-screenshot-2023-08-05-181817.png) ##### Pianificazione e Apprendimento L'apprendimento nel RL si basa sulla pianificazione. La *pianficazione* implica la conoscenza del modello associato all'ambiente, es. il lancio di un dado che implica che il *valore medio detto anche ritorno medio* dell'azione è 3,5 ovvero 1\*1/6+2\*1/6+3\*1/6+4\*1/6+5\*1/6+6\*1/6. **NB**: il modello è l'ambiente e normalmente NON lo conosciamo. L'apprendimento, è la fase successiva alla pianificazione e implica l'iterazione con l'ambiente e prevede il calcolo della media empirica ovvero la media dei valori ottenuti dall'iterazione con l'ambiente. Quindi con la pianficazione e l'apprendimento, l'agente migliora la policy. Entrambi guardano avanti nel futuro calcolando i valori cercando il miglioramento della policy. ##### Tipologie di algoritmi applicabili al RL Di seguito viene rappresentata la tassonomia (categorizzazione) delle varie tipologie di algoritmi applicabili nell'ambito del RL. [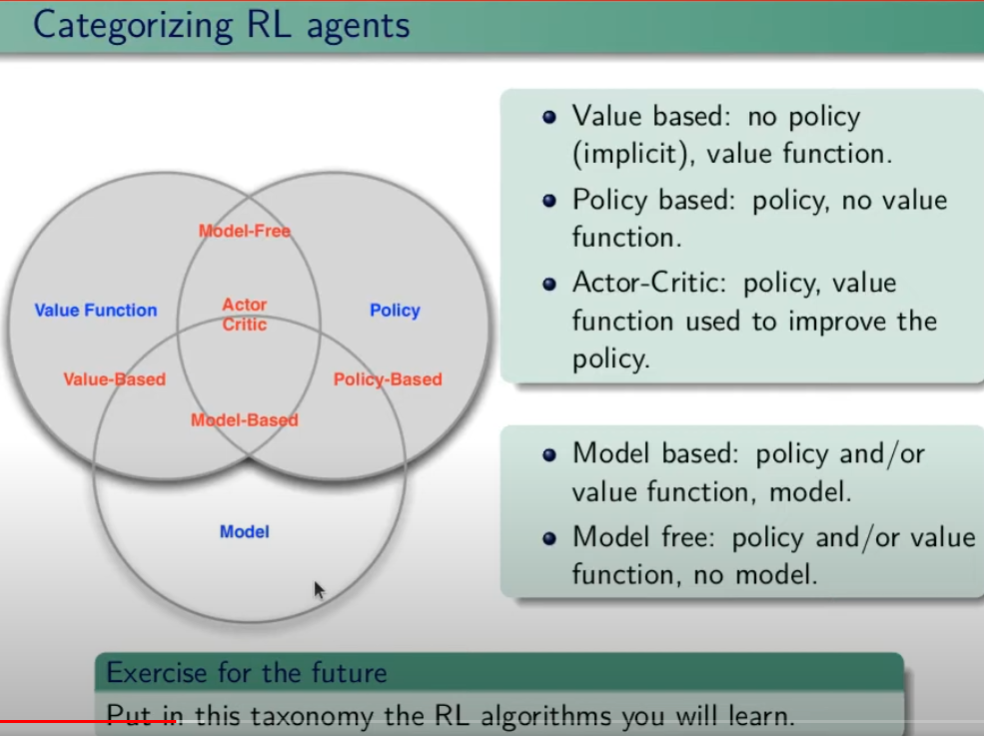](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/peun6Td4yIm70rWz-screenshot-2023-08-05-181817.png) ##### Esplorazione vs Sfruttamento E' l'eterno dilemma, ovvero provo sempre nuove soluzioni o sfrutto sempre quelle che già conosco. Entrambi vanno utilizzati per "allenare" la rete rete neurale. (vedremo più avanti) ##### Processi decisionali di Markov (MDP) I processi decisionali di Markov si basano sulla gestione degli stati. Gli stati vengono rappresentati come dei cerchi dove all'interno è presente una lettera che lo rappresenta. Il pallino nero invece è l'azione. Nello schema sotto rappresentato vediamo che, partendo dallo stato "u", la risposta dell'ambiente a fronte dell'azione "a" di tipo probabilistico (aleatoria) e quindi non deterministico, è di 0,7 con un reward di +3 che ci porta di v, oppure 0,3 con reward -1 che ci porta in "w". Se invece a fronte di una azione (pallino) ci fosse stato una unica determinazone della riposta dello stato T+1 anzichè due o piu, allora la risposta sarebbe stata derministica. Es. leggendo la risposta dell'ambiente a fronte dell'azione a (nel caso dello 0,7 - 70%) è: la probabilità di arrivare in "v" con una ricompensa di +3, dato che sono partito dallo stato iniziale "u" e ho fatto l'azione "a". [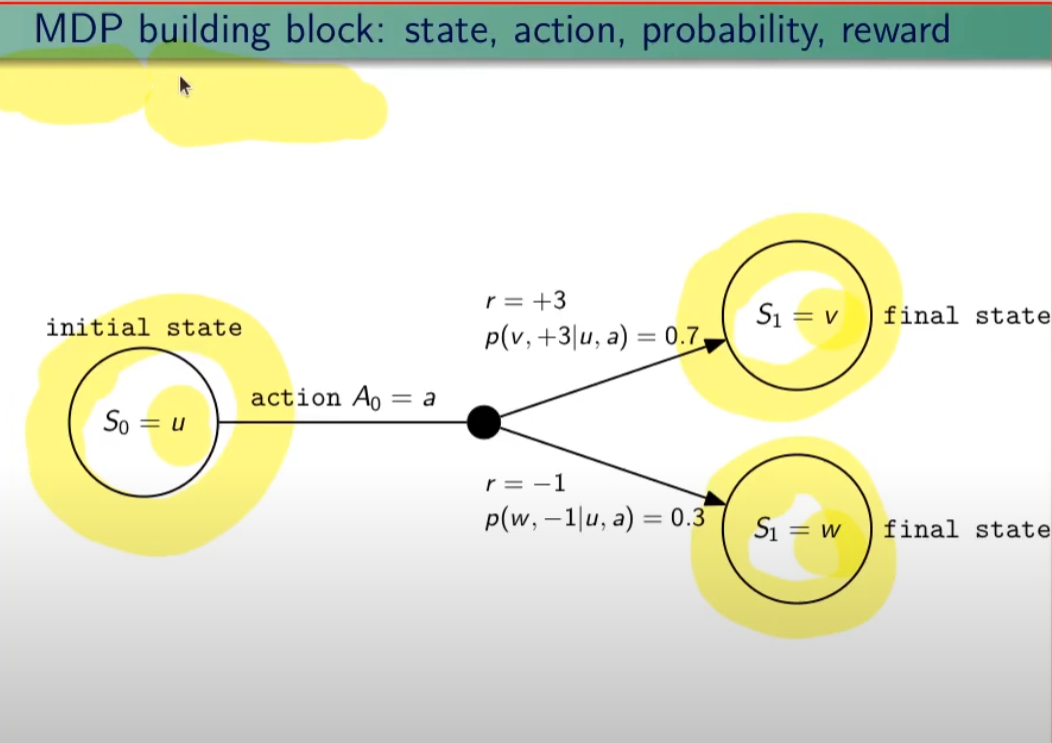](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/CBONlOh3cKHYN1g8-screenshot-2023-08-06-105538.png) Sempre rimandendo nel diagramma sopra riportato, qual'è la probabilità di andare in "w" con una reward di 42? (vedi figura sotto) [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/fYp9S8GLa0xcJPYC-screenshot-2023-08-06-105538.png) La risposta è zero in quando deve verificarsi la combinazione stato + reward che in questo caso non esistendo è quindi pari zero. NOTA: lo **stato terminale si indica con un quadrato**. Ora semplifichiamo un attimo lo schema per renderlo più leggibile come sotto riportato: [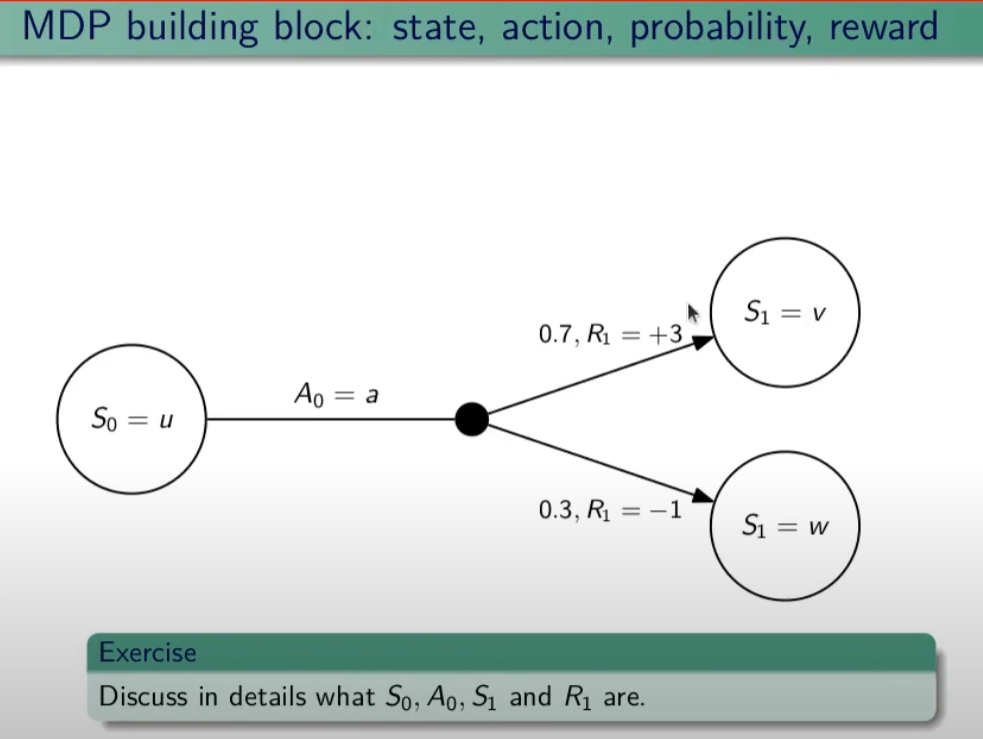](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/m4aqiIrgbyI3KzVp-screenshot-2023-08-06-105538.png) Nello specifico la differenza tra S0 e S1 indica la situazione dello stato "S" al tempo T. Ovvero S0 è lo stato iniziale, mentre S1 è sempre lo stato S ma al tempo T+1 e può valere "w" o "v" a seconda della probabilità. Se ci fosse uno stato successivo S2 dovremmo considerare le probabilità di transizione da S0 a S1 e da S1 a S2. **La rappresentazione** è quindi un **g****rafo orientato** in quanto unidirezionale. i tondi sono le azioni e gli archi i risultati probabilistici delle azioni. Ho quindi un insieme di stati S e di azioni A e di rewards R. Dopo ogni azione ho quindi una distribuzione di probabilità su SxR. Per ogni coppia di stato azione ho una distribuzione di probabilità. Conoscere il modello significa quindi conoscere la distribuzione di probabilità. Introduciamo anche il fattore di sconto gamma che vale sempre di meno all'allungarsi della distanza di tempo in modo che l'agente sia incentivato a trovare la soluzione migliore più velocemente. La funzione p rappresenta quindi il modello, è quindi la probabilità di transizione dallo stato al tempo T-1 allo stato al tempo T. (a fronte di una certa azioen e relativa ricompensa) Generalizzando quanto sinora detto: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/z6qe3aFMeRyopre3-screenshot-2023-08-06-105538.png) > dove il simbolo **|** (pipe) indica che un elmento "a" è condizionato **da** "b", es. "a | b". Occhio che per es. P(a,b) è la probabilità dato in input "a" e "b" mentre invece P(a|b) significa la probabilità dato "a" e condizionato a "b" MA "a" puà assumere più valori in B. > > dove il simbolo **~** (tilde) indica che uno stato S è preso da una certa distribuzione di probabibilità P, es. S ~ P(...) Esercizio: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/7Jgs7CO0F5XrMrvi-screenshot-2023-08-06-105538.png) nota: ricordare che il simbolo 𝔼 rappresenta il ritorno atteso ovvero il valor medio dei ritorni. In pratica 𝔼 rappresenta il valore medio (**media dei valori pesati**) delle ricompense che posso ottenere in un determinato stato S. Questo perchè in uno stato protrei avere una distribuzione di probabilità che per es. a fronte di una azione possono scaturire più azioni con associata una proababilità e un ricompensa ciascuna. es: [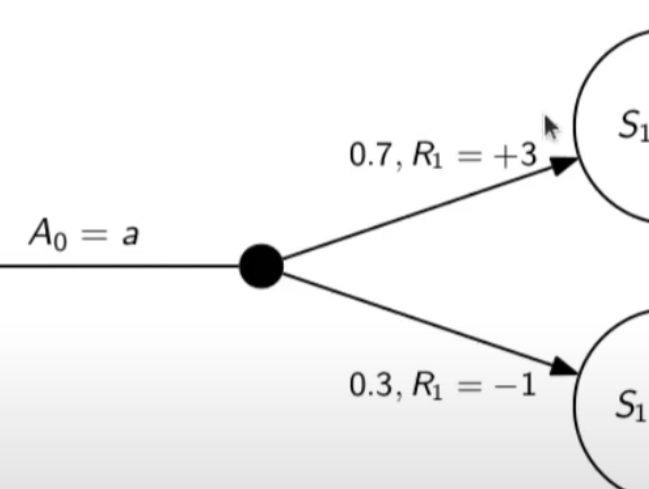](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/3i4xk2Qw7p6xnalW-image.png) 1\) [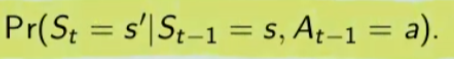](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/dum07P5Hu1H17p7K-screenshot-2023-08-06-105538.png) La prima riga si legge così: la probabilità che un stato S al tempo T sia s' condizionato al fatto che lo stato precedente fosse s e che io abbia fatto precendetemente una derminazione azione a. Quindi si vuole sapere la probabilità di essere nello stato s' nel caso in cui nello stato precedente s sia stata eseguita l'azione a. Per ricavare questa probabilità bisogna partire la formula generica MDP che tiene conto delle rewards, ovvero: [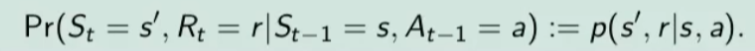](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/F1MTVaLRW6WJ3dLC-screenshot-2023-08-06-105538.png) quindi per rispondere al prima quesito dobbiamo sommare tutte le rewards in modo che rimanga la sola probabilità che ci porta allo stato s', in quanto non vogliamo la probabilità che esca s' e r, ma vogliamo solo la probabilità che esca s', oovero: [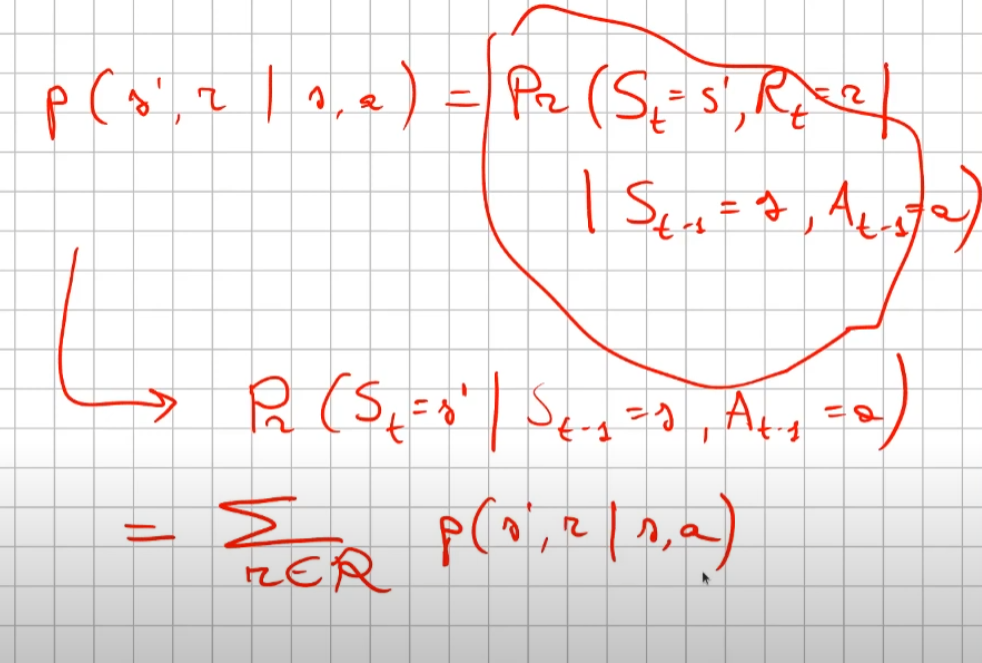](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/Iu0EBNEKNv6MbeG6-screenshot-2023-08-06-105538.png) perchè sommando **tutte** le rewards ho la certezza di finire nello stato s'. Sommare tutti gli "r" si dice anche saturare tutti gli indici r. 2\) [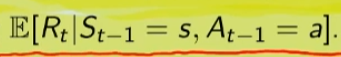](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/eTQueLACsuiwp203-screenshot-2023-08-06-105538.png) In questo caso invece si desiderata la ricompensa media (variabile aletoria) al tempo "t" condizionata dal fatto che al tempo t-1 partissi dallo stato "s" e facessi l'azione "a". Quindi il valore medio della ricompensa sarà la sommatoria di tutte le ricompense ciascuna di esse moltiplicate per la propria probabilità di uscita, ovvero: [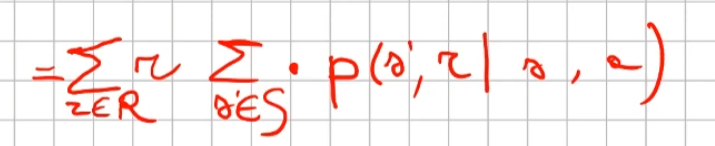](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/hx0RkIYRgYL4hsW1-screenshot-2023-08-06-105538.png) dato che in questo caso vogliamo la reward media al tempo t, come nel caso 1) dobbiamo "saturare" un fattore, in questo caso sono gli stati. Quindi per tutti gli stati s' moltiplichiamo la probabilità ritornata dall'azione a nello stato "s" a t-1 per tutte le reward. La prima sommatoria estrare tutte le reward che vanno a moltiplicare le corrispittive probabilità. Moltiplicando reward per la probabilità si ottinene la reward media. (vedi esempio del valotre medio del lancio del dado, dato dalla sommatoria del valore di ciacuna faccia del dado per 1/6 per un totale di 3,5) 3\) per ora non viene spiegato. ##### Dinamica del MDP: rappresentazione tabbellare Una delle tecniche più basiche di rappresentazione delle transizioni da uno stato all'altro fa uso di matrici di valori che indicano la probabilità di transizione da uno stato all'altro. Se per esempio un sistema ha 4 stati, la tabella sarò composta da una mtrice di 4x4. Ovviamente questo metodo funziona con sistemi i cui stati sono molto limitati, non per funziona con sistemi complessi come per es. gli scacchi o la dama. Facciamo un esempio, calcoliamo su questo MDP delle quantità: [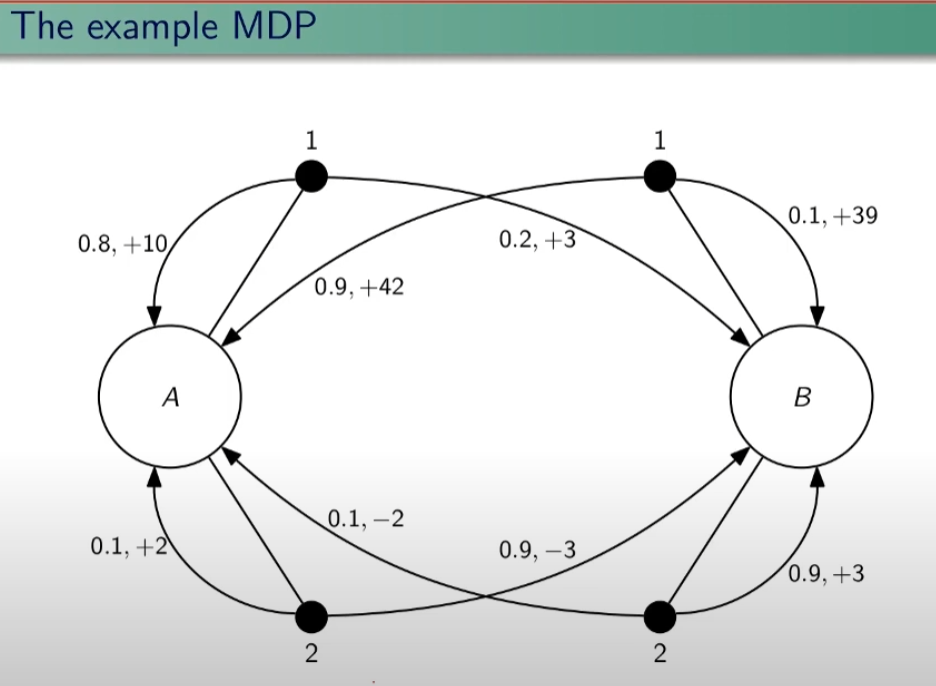](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/BhNOCEtvvLgqiw8M-screenshot-2023-08-06-105538.png) Iniziamo con il calcolo di una matrice di transizione detta matrice stocastica, in queso caso avendo due stati la matrice è 2x2, nelle celle della matrice andremo ad inserire le probabilità di transizione da uno stato all'altro. Nell'esempio sotto riportato andremo a calcolare la matrice associata all'azione 1. La peculiarità di questa matrice è che la somma di ciascuna riga da sempre 1 - 100%.| P = 1 (azione 1) | A | B |
| A | 0,8 | 0,2 |
| B | 0,9 | 0,1 |
| R = 1 (azione 1) | 10\*0,8 + 3\*0,2 = **8,6** | 0,9\*42+0,1\*39 = **41,7** |
| s (stato partenza) | a (azione) | s' (stato di arrivo) | r (ricompensa) | p(s',r | s,a) probabilità |
| A | 1 | B | 3 | 0,2 |
| ... | ||||
Come faccio a calcolare pi' (primo) ? be faccio tutte le azioni **"a"** possibili, faccio "**one step looking forward**", ovvero faccio un passo avanti compiendo un'azione sola, guardo cosa succede al passo successivo chiedento all'ambiente cosa può succedere con quale probabilità. Facendo queste azioni prendo quella che massimizza il ritorno.
*Ma quando una policy è migliore di un'altra? beh quando per ogni stato s, applicando la nuova policy **π'**, il valore dello stato è maggiore-uguale al valore della vecchia policy. Nella pratica faccio N iterazioni compiendo N traiettorie fino a quando i valori convergano, a questo punto confronto tutti gli stati valori con quelli precedenti, se sono migliori allora faccio un altro giro, loppando fino a quando gli stati valori sono uguali al precedente, il che identifica la policy migliore.* Ma cosa vuol dire nella pratica? Supponiamo di avare uno stato "s" e un'azione "a1" che porta in tre stati (s',s2, s3), dove per ognuno dei tre stati avviamo una probabilità di entrare in ciascuno stato con una relativa reward, abbiamo anche il valor medio totale dello stato **V*****π*** di ciascun stato che era stato precedentemente calcolato applicando la policy. (vedi schema sotto riportato) [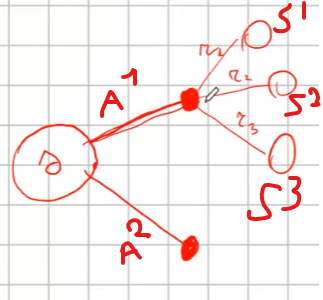](https://cms.marcocucchi.it/uploads/images/gallery/2024-11/e1QOvMl5ike2Fqje-image.png) Ora per ogni azione (es. a1 e a2) voglio calcolare il valore medio dell'azione stessa che significa calcolare il valore delle "cose/fatti" che possono accadere pesati per le probabilità. Nell'esempio sopra riportato significa prendere la probabilità che accada s' con la relativa reward r dato lo stato s con l'azione a1, ovvero: p(s',r | s, a1)\*(r+Vπ(s')) -> probabilità di andare in s' con l'azione a1 che moltiplica la somma della reward ottenuta per andare nello stato s' + il valore medio totale dello stato s'. Questa operazione va ripetuta per ogni stato raggiunto dall'azione **a**1, ovvero nel nostro caso s',s2, s3 e sommata per questi tre stati quindi: **Qπ(s,a) = Σ (**xx**) p(s**xx**,r | s, a**xx**)\*(r+Vπ(s**xx**))** dove **xx** è **s',s2,s3** Poi analogamente calcoliamo il **Qπ(s,a2)** e ne calcoliamo il massimo tra *argmax* (**Qπ(s,a),Qπ(s,a2**)) e scegliamo **l'azione** associata al **Qπ massimo**. In questo modo andiamo a miglioare la policy in maniera "**greedy**" ovvero cercando di massimizzare il valore. Il nome di questo algoritmo di chiama "policy iteration". Il cui pseudo codice è sotto riportato: [](https://cms.marcocucchi.it/uploads/images/gallery/2024-11/1NsL1E2c7IUqDzW9-image.png) L'algoritmo alterna la valutazione (evaluation) della policy al improvement fino a che non ottengo la policy. [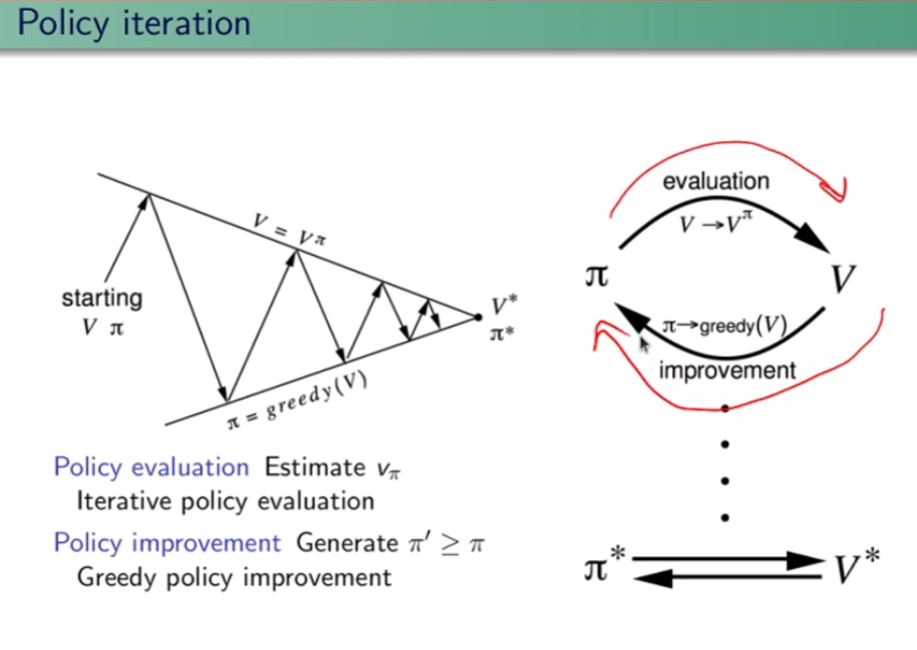](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/kDnCgz7zp7hbd2qY-screenshot.png) dove: 1\) inzializza i valori randomicamente e seleziona una policy casuale 2\) applica la valutazione delle policy, ovvero calcola V\_pi 3\) miglioramento, ovvero: - facciamo un ciclo sugli stati S (detta anche "*sweep*") -> NB essendo pianificazione di un MDP a stati finiti rende la cosa fattibile, in reatà in giochi come "go" non è possibile in quanto gli stati sono un numero enorme, ma questa è un'altra storia) - ciclo su tutte le azioni dello stato che sto valutando - salvo la vecchia azione (V(sxx) - effettuo la nuova azione e vedo quale valore V(sxx) otttengo - confronto vecchia e "nuova funzione valore" V(S) se il valore della nuova azione è miglioare allora l'agoritmo non ha ancora trovato la policy migliore e quindi aggiorno la policy con l'azione miglioare e continuo a looppare - fatti passare tutti gli stati se la policy non è stabile riparto dal punto 2 - in generale il tutto looppa finchè i valori non convergono il che significa che tra uno sweep e l'altro non ci sono grandi variazioni Ricordo che la pianficazione si può applicare solo quando disponiamo del modello, che è il caso più facile e poco probabile che accada nel RL. Di seguito l'algoritmo completo ```python from envs.gridworld import GridworldEnv import numpy as np def policy_evaluation(policy, env, discount_factor=1.0, theta=0.001): """ :param policy: [A,S] matrice di shape (rango = 29 a due domensioni che rappresenta la policy, dove sulle riche ci sono gli stati e sulle colonne le azioni :param env: rappresentazione dell'ambiente :param discount_factor: fattore di sconto gamma :param theta: valore che termina la valutazione della policy una volta che la funzione stato valore è sotto questa soglia :return: ritarna la tabella stato valore (V) contenente i valori ottimali per arrivare allo più efficacemente allo stato terminale in pratica l'algoritmo incentiva ad andare verso lo stato il cui valore è più alto, es. tra due stati che valgono rispettivamente- 14 e -20 si va verso il valore pià grande ovvero -14. NOTA: - le azioni sono: 0 = su, 1 = dx, 2 = giù, 3 sx - la reward è sempre -1 tranne negli stati terminali - negli stati terminali le azioni non effettuano spostamento di stato. """ # inizializzamo la funzione stato valore V, per semplificare la vita li portiamo a zero # dove il valore è il valore di OGNI STATO V = np.zeros(env.nS) # il ciclo deve fermarsi solo quanto la qta delta calcolata è minuore o uguale a theta passaggi = 0 while True: delta = 0 passaggi += 1 # per ciscuno stato effettuo un "full backup" # questo primo ciclo fa passare tutti gli stati for stato in range(env.nS): v_appo = 0 # questo il ciclo fa la sommatoria delle azioni # ovvero esegue tutte le azioni possibili nello stato s azioni_stato = enumerate(policy[stato]) for azione , policy_prob in azioni_stato: # per ciascuna azione chiedo all'ambiente in quale stato finisco, la probabilità di finirci, la ricompensa # e se eventualmente è lo stato finale # NB: la situazione NON è vera in quanto stiamo facendo "esperienza" senza fare un passo, questo non è # vero RL è pianificazione # Da notare che questo ciclo è utile solo nel caso in cui a fronte di una azione ci possono essere diversi # stati destinazione con diverse probabilità, nel nostro caso ci sarà sempre e solo uno stato destinazione # con probabilità (env_prob) pari a 1 for env_prob, next_state, reward, done in env.P[stato][azione]: # equazione di Bellman # probabilità dell'azione per la probabilità della transizione v_appo = v_appo + policy_prob * env_prob * (reward + discount_factor * V[next_state]) # delta misura l'errore su tutti gli stati, ovvero misura la differenza tra tutti gli # nella passata precedente N-1 e l'attuale N. # Nella pratica significa che per ogni stato il delta massimo trovato è quello indicato nella varibile # e quindi potrà poi essere comparato con theta per terminare la valutazione della policy delta = max(delta, np.abs(v_appo - V[stato])) V[stato] = v_appo # stampo la tabella degli stati # vr = V.reshape(env.shape).round(3) # print(vr,stato,passaggi,'%5.15f' % delta) # input() # finiamo la valutazione una volta che il valore è sotto la soglia theta if delta < theta: break return np.array(V), passaggi def policy_improvment (env, policy, policy_evaluetion_fn, discount_factor=1.0): """ Funzione che migliora la policy iterativamente :param env: ambiente openAI :param random_policy: passiamo una policy iniziale :param policy_evaluetion_fn: funzione che valuta la policy e restituisce gli stati funzione valore V :param discount_factor: fattore di sconto gamma :return: ritorna una tupla che che tiene la nuova policy ottimale, gli stati valori e il totale passaggi effettuati """ def one_step_lookahead(state, V): """ funzione helper che calcola il valore di tutte le azioni dato uno stato :param state: :param V: :return: Q-value -> un vettore di lunghezza env.nA ovvero tutte le azioni possibili nello stato che contiene il valore funzione stato per ogni azione. """ A = np.zeros(env.nA) # prendo tutte le azioni possibili nello stato passato in input alla funzione for a in range(env.nA): # come reagisce l'ambiente in quello stato # per ogni azione ottengo il valore totale medio # NB: interrogo l'ambiente e sarà lui a dirmi con quella azione in quali stati andrò e con quale probabilità e reward for prob, next_state, reward, done in env.P[state][a]: # calcolo il valore medio di tutti gli stati raggiungibili effettuando l'azione "a". A[a] += prob * (reward + discount_factor * V[next_state]) return A passaggi = 0 # ciclo di controllo. while True: passaggi += 1 # valutiamo la policy V, psg = policy_evaluation_fn(policy, env, discount_factor) # setto il flag che mi interromperà il loop while policy_stable = True # estraggi tutti glistati # SWEEP for s in range(env.nS): # effetuo lo "one step ahead" per capire quali valori mi restituisce l'azione che ho deciso di action_values = one_step_lookahead(s, V) ############# calcolo l'azione migliore # IMPROVMENT ############# best_a = np.argmax(action_values) # sceglo l'azione con probabilità maggiore tra quelle presente nella VECCHIA (attuale) policy # per quello stato, nella pratica estrae l'indice prev_policy_action = np.argmax(policy[s]) # confronto l'azione delle vecchia policy con quella trovata dall'improvment e verifico se coincidoni # se non coincidono allora la policy non è ancora stabile e quindi non ottimale. if prev_policy_action != best_a: policy_stable = False # setto l'indice dell'azione che massimizza il valore calcolato a 1 per cambiare la policy ottimizzandola policy[s] = np.zeros(env.nA) policy[s][best_a] = 1 # se la policy è stabile allora abbiamo trovato quella ottimale, quindi interrompo il ciclo principale ed esco if policy_stable: break return policy, V, passaggi # 0 su 1 dx 2 giù 3 sx # instanzio l'ambiente griglia env = GridworldEnv([4,4]) print (env.nS) print (env.nA) env.reset() env._render() env.step(1) print() env._render() env.step(1) # definiamo una polcy generica, in pratica per ogni stato del mondo griglia associo 4 probabilità di eseguire una azione, le probabilità sono tutte al 25% random_policy = np.ones( [env.nS, env.nA])/env.nA print(random_policy) policy_ottimale, V, passaggi = policy_improvment (env, random_policy, policy_evaluation) #V,passaggi = policy_evaluation(random_policy, env) v = V.reshape(env.shape).round(0) print(v,passaggi) # print() print(policy_ottimale) ``` ([https://www.youtube.com/watch?v=QY3yxYyK4wM&list=PLMee1hSjLKdAL16E-7EzqHXsGOgzo8iro&index=13)](https://www.youtube.com/watch?v=QY3yxYyK4wM&list=PLMee1hSjLKdAL16E-7EzqHXsGOgzo8iro&index=13)) ##### Iterazione di valore Con queste tipologie di algoritmi vogliamo **ottimizzare **le policy combianando la policy evaluation e la policy improvement. Nel iterazione della policy ricordiamo che l'algoritmo è diviso in due parti, la prima che riguarda la valutazione della policy (evaluation) e la seconda che la migliora agendo in maniera "greedy" ovvero scegliendo l'azione che massimizza il valore medio atteso prendendo la argmax dei valori restituiti dal "one step look ahead". Nella iterazione di valore invece l'alogoritmo di semplica e indirettamente si ottimizza combianando i due step secondo lo pseudo codice sotto riportato: [](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/cm8jcWDDzKMFXy7C-image.png) che in pratica applica l'equazione di Bellman sostituendo direttamente il valore medio atteso della funziona stato valore.: [](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/XeT0wzWY6TeNbQZy-image.png) di seguito l'algorirmo rivisto, la differenza in termini di performace rispetto al precedente è notevole. ```python from envs.gridworld import GridworldEnv import numpy as np import time # funzione per misurare il tempo di esecuzione di una funzione tramite un decorator # basterà1: # 1) importare la funzione -> from objs.TimerDecorator import timing_decorator # 2) decorare la funzione da misurare con @timing_decorator def timing_decorator(func): def wrapper(*args, **kwargs): start = time.time() original_return_val = func(*args, **kwargs) end = time.time() print("time elapsed in ", func.__name__, ": ", end - start, sep='') return original_return_val return wrapper from envs.gridworld import GridworldEnv import numpy as np from utils.TimerDecorator import timing_decorator @timing_decorator def value_itaration(env, theta = 0.00001, discount_factor=1.0): """ Funzione che migliora la policy policy_improvment :param env: ambiente openAI :param theta: valore che termina la valutazione della policy una volta che la funzione stato valore è sotto questa soglia :param discount_factor: fattore di sconto gamma :return: ritorna una tupla che che tiene la nuova policy ottimale, gli stati valori e il totale passaggi effettuati """ def one_step_lookahead(state, V): """ funzione helper che calcola il q-value (valore) di tutte le azioni dato uno stato :param state: :param V: :return: Q-value -> un vettore di lunghezza env.nA ovvero tutte le azioni possibili nello stato che contiene il valore funzione stato per ogni azione. """ A = np.zeros(env.nA) # prendo tutte le azioni possibili nello stato passato in input alla funzione for a in range(env.nA): # come reagisce l'ambiente in quello stato # per ogni azione ottengo il valore totale medio # NB: interrogo l'ambiente e sarà lui a dirmi con quella azione in quali stati andrò e con quale probabilità e reward for prob, next_state, reward, done in env.P[state][a]: # calcolo il valore medio di tutti gli stati raggiungibili effettuando l'azione "a". # equazione di "punto fisso" A[a] += prob * (reward + discount_factor * V[next_state]) return A # inizializziamo gli stati con dei valori casuali a piacere (array di N stati) V = np.zeros(env.nS) while True: # inizializzo la variabile che condizione lo stop del loop delta = 0 # aggiornare di stati for s in range(env.nS): # guardo uno step avanti restituendo la funzione stato valore di ogni azioni che può essere fettuata nello stato best_action_value = np.max(one_step_lookahead(s,V)) # confronto l'azione con i valore dello stato nell'itezione precedente delta = max(delta, np.abs (best_action_value - V[s])) # salvo lo stato valore V[s] = best_action_value # se il delta è sotto theta allora i valori sono prossimi alla convergenza desiderata if delta < theta: break # ora dagli stati valore ricavo la policu V*(s) -> Q*(s,a) # inizilizzo la policy policy = np.zeros([env.nS,env.nA]) for s in range (env.nS): azione = np.argmax(one_step_lookahead(s,V)) policy[s][azione] = 1.0 return policy, V # 0 su 1 dx 2 giù 3 sx # instanzio l'ambiente griglia env = GridworldEnv([4, 4]) # print(env.nS) # print(env.nA) env.reset() # env._render() # env.step(1) # print() policy_ottimale, V, = value_itaration(env) # V,passaggi = policy_evaluation(random_policy, env) print(V) # # print() print(policy_ottimale) ``` Esercizio 2 Abbiamo un certo capitale inferiore a 100 (es. 99 o 1 o 44) e lo scopo è arrivare esattamente a 100. (valori oltre il 100 non sono considerati, il goal è esattamente a 100) Possiamo scommetere solo il capitale a nostra disposizione lanciando una monetina scommettendo quello che vogliamo sulla base di quello che abbiamo. (es. ho 70 lancio la monetina e scommetto per es. 30 per arrivare a 100, se perdo vado a 40 se vinco vado a 100 e ho terminato il gioco vnicendo. Ovviamente se arrivo a zero ho perso.Il problema può essere modellato come un MDP, senza 1) fattore di sconto, 2) episodico, ovvero da traiettorie (successione di azioni, rewards e stati) di lunghezza finita che si concludono in uno (o più) stato/i terminale/i raggiungible/i e 3) finito ovvero che stati e azioni sono finiti.
In generale quando le ricompense sono tutte zero, tranne che nella transizione dallo stato precedente allo stato terminale e lo stato terminale stesso, dove in questo caso vale 1, allora la funzione stato valore indica la probabilità di vittoria in quello stato.
Ricodiamo che: il valore dello stato è media con la probabilità di tutte le traiettorie possibili della ricompensa totale.
```python import numpy as np """ Abbiamo un certo capitale inferiore a 100 (es. 99 o 1 o 44) e lo scopo è arrivare esattamente a 100. (valori oltre il 100 non sono considerati, il goal è esattamente a 100) Possiamo scommettere solo il capitale a nostra disposizione lanciando una monetina scommettendo quello che vogliamo sulla base di quello che abbiamo. (es. ho 70 lancio la monetina e scommetto per es. 30 per arrivare a 100, se perdo vado a 40 se vinco vado a 100 e ho terminato il gioco vincendo. Ovviamente se arrivo a zero ho perso. Il problema può essere modellato come un MDP, senza 1) fattore di sconto, 2) episodico, ovvero da traiettorie (successione di azioni, rewards e stati) di lunghezza finita che si concludono in uno (o più) stato/i terminale/i raggiungible/i e 3) finito ovvero che stati e azioni sono finiti. In pratica lo stato rappresenta il capitale posseduto, e in base a quello la policy dovrebbe cercare di assumere il comportamento ottimale. In prima battuta va definito il modello. Il modello restituisce sempre ricompensa 0 tranne quando arrivo nello stato terminale 100. Notare che la ricompensa non è quanto stiamo guadagnando in quanto l'obiettivo è arrivare a 100 e non accumulare più soldi possibili. """ def values_iteration_for_gamblers(probab_monetina = 0.5 , theta=0.0001, discount_factor=1.0): """ :param probab_monetina: probabilità che esca testa :param theta: valore delta di convergenza :param discount_factor: fattore di sconto :return: policy e funzione stato valore """ def one_step_look_ahead(in_capital, V, rewards, probab_monetina, discount_factor): """ In base allo stato in cui mi trovo, ovvero il capitale a mia disposizione, effettuo una possibile giocata per tutte le possibili giocate a mia disposizione. Ovvero se ho un capitale di 40, farò una giocata partendo dalla somma 1 fino al massimo a mia dispisizione. (ovvero 40) La funziona ci dice nella pratica per ogni azione fatta con il capitale passato quanto vale quella azione. :param capitale: capitale del giocatore (rappresentato dallo stato) :param V: stati valore :param rewars: ricompense :return: ritorna l'elenco dei valori medi ottenibili effettuato tutte le azioni nello stato ovvero del capitale passato in input """ # inizializzo le azioni possibili in ogni stato A = np.zeros(101) # passato il capitale a disposizione, calcolo tutte le possibili giocate da quella minima (1) al massimo # che posso giocare con il capitale a disposizione passato in input. # il min(capital, (100-capital)) serve per calcolare il capitale giocabile considerando che # non posso andare oltre 100 anche se il capitale a mia disposizione lo consetirebbe capitale_giocabile = min(in_capital, (100 - in_capital)) # effettuo tutte le giocate possibili for giocata_in_soldi in range(1,capitale_giocabile+1): # a questo punto per ogni giocata vedo il valore medeio di quello che può succedere effettuando # tutte le giocate possibili. A[giocata_in_soldi] = probab_monetina * (rewards[in_capital + giocata_in_soldi] + V[in_capital + giocata_in_soldi] * pow(discount_factor, giocata_in_soldi)) \ + (1 - probab_monetina) * (rewards[in_capital - giocata_in_soldi] + V[in_capital - giocata_in_soldi] * pow(discount_factor, giocata_in_soldi)) # array che indica per ogni azione fatta con il capitale a mia disposizione, quanto vale ciascuna azione. return A ###################### ######## INIZIO ###### ###################### # creo un array di 101 elementi che rappresenta le rewards dove: # - l'elemento zero è lo stato di perdita del gioco -> stato terminale # - l'elemento 101 è lo stato di vincita del gioco -> stato terminale # tutti gli stati avranno una rewards pari a zero tranne l'ultimo (100) che avrà reward = 1 rewards = np.zeros(101) # ricordo che è zero based, quindi l'elemento 100 è il 101 rewards[100] = 1 # inzializzo la funzione stato valore con dei valori a "caso" facciamo zero per facilitare V = np.zeros(101) # creo la policy ottimale policy = np.zeros(101) # ciclo principale while True: # inizializzo la variabile che verrà utilizzata per interrompere i ciclo di valutazione della policy # fino alla sua convergenza. delta = 0 # simulo tutti le possibili giocate con tutti i possibili capitali a mia disposizione # fa passare tutti gli stati for giocata in range (1,100): # verifico quanto valgono tutte le giocate con il capitale simulato # faccio tutte le azioni possibili A = one_step_look_ahead(giocata, V, rewards, probab_monetina, discount_factor) # determino il valore della giocata più alto best_action_value = np.max(A) # verifico se la giocata è migliore della precedente delta = max(delta, np.abs(best_action_value-V[giocata])) # salvo il valore migliore nella funzione stato valore V[giocata] = best_action_value # verifico se interrompere il loop perchè la funzione stato valore sta converendo if delta < theta: break # questo ciclo indica come giocare in ogni stato, dove lo stato rappresenta il capitale posseduto # serve solo per identificare l'azione megliore da intraprendere basandosi sulle stati valori ottimali precedentemente # calcolatir for giocata in range (1,100): A = one_step_look_ahead(giocata, V, rewards, probab_monetina, discount_factor) best_action_value = np.argmax(A) policy [giocata] = best_action_value return policy,V policy, V = values_iteration_for_gamblers(discount_factor=1) # tampo la funzione valore for i in range(101): if i % 10 == 0: print() print (" %i-%s"%(i,V[i]), end='') print () # stampo la policy for i in range(101): if i % 10 == 0: print() #print (" %i-%s"%(i,policy[i]), end='') print(" %i-%s" % (i,policy[i]), end='') # print (policy) # print (np.reshape(policy,(10,10))) ``` # Sessione 2 #### Metodi Model free Nel capitolo precedente abbiamo svolto un lavoro di ***pianificazione* **e **non** di *appredimento per rinforzo* in quanto avevamo il modello (ambiente) che ci diceva con quale probabilità svolgeva le azioni. La policy (pi) era in qualche modo nota, questo però non rappresenta la realtà in quanto il modello, nella natura delle cose, non ci viene dato a priori, dobbiamo quindi trovare un modo per ricavarlo, come fare? Bene bisogna quindi interrogare l'ambiete e con le risposte ottenute ricavare in quale modo il modello. Abbiamo quindi a che fare un metodi **"model free" in quanto il modello NON è noto a priori.** Da notare che possiamo comunque interagire con l'ambiente tramite esperienza, ovvero: 1. parto da uno stato che posso scegliere in maniera casuale 2. scelgo l'azione tramite la mia policy e vedo cosa succede 3. torno al punto 1 e così via fino alla fine dell'episodio **SPIEGONE**: Tutto questo fino a quando otterremo la "policy ottimale", ovvero facendo la media di tutti i ritorni Gt. Quindi per via delle l*egge dei grandi numeri* possiamo approssimare il valore medio atteso ([](https://cms.marcocucchi.it/uploads/images/gallery/2025-04/Icj36K8XriPTKO3p-image.png)) con la semplice media empirica. Ricordo che il valore atteso (**E**) è quello che si calcola con le probabilità di transizione, mentre la media empirica è la semplice somma di tutti i valori diviso il numero totale dei valori. Quindi quando il numero di valori tende a infinito allora il valore converge al valore atteso. ##### Predizione E' model free perchè non abbiamo a priori il modello, cosa che invece avevamo all'inizio del corso con la *pianificazione*. Dovremo quindi far uso di "stimatori" in grado di ricostruire nella maniera più federe possibile il modello. Dobbiamo quindi fare un lavoro di predizione, per fare questo abbiamo due metodi, il primo detto "Monte Carlo" mentre il secondo detto "Temporal Difference" **Metodo Monte Carlo ** Il metodo **Monte Carlo (MC)**, nella pratica voglio "**imparare**" il valore delle mie azioni iteragendo con l'ambiente. *Banalmente compio azioni "a caso" e poi tengo traccia delle media aritmetica degli episodi che faccio.* Svolgo quindi un episodio partendo dallo stato k e raccolgo tutti i valori, e relative reward, degli stati fino allo stato terminale. Terminato un episodio G(T) ne faccio altri N, poi, per ottnere il valore V(Sxx) faccio la media aritmetica di tutti i G(T) ottenuiti partendo dal quello stato "S" e salvo il valore ottenuto nello stato s. Svolgo questo lavoro per N volte per tutti gli M stati, in questo modo a tendere, sempre per la legge dei grandi numeri, mi avvicino al valore reale dello stato. (da notere che con questo metodo non devo inizializzare gli stati in quanto interrogo subito l'ambiente) **NB**: MC è un metodo "off line" ovvero che impare dopo aver finito l'episodio. Questo metodo impara il valore della policy dall'esperienza. Da qui deriva il concetto di "**boostrapping**", ovvero quando calcolo il valore Vk applicando la funzione "one step looking ahead" andando ad esplorare gli stati successivi s', utilizzo i valori Vk calcolati in precedenza per ricalcolare l'attuale valore Vk. Da notare che nei metodi con bootstrapping bisogna stimare i valori di **tutti** gli stati altrimenti perde efficacia. Di qui la versione più semplice dell'algoritmo in pseudo-codice: [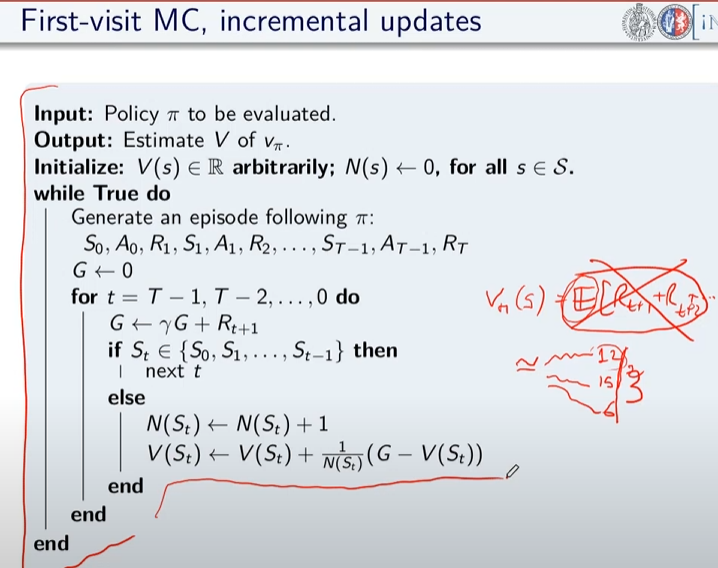](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/EnMYIzULTO5BiNjZ-image.png) da notare la formula sottolineata che rappresenta la ***forma incrementale della media aritmetica***, ovvero come aggiungere un valore ad una media considerando il suo peso rispetto alla media stessa. In pratica si tratta di sommare la media a (valore meno la media)/numero totale dei valori. come funziona: - inzializza la funzione valore con dei valori a caso (anche *zeros*) - facciamo **un episodio**, ovvero memorizzare: - tutti gli stati - tutte le azioni - tutte le ricompense - fino alla fine - partiamo dalla fine dell'episodio (stato Rt) e inzializziamo il valore Gt a zero - procedo **risalendo** gli stati partendo da quello terminale che vale zero, vado a T-1 del quale prendo la **ricompensa **e la **sommo** a quella dello stato se segue (in questo caso quello finale) - procedo risalendo in questo modo (sommando) fino allo stato iniziale - calcolo il valore V(St) come la media dei ritorni di tutti gli stati precendenti (da quello terminale a quello in elaborazione) Di seguito il codice che implementa l'algoritmo: ```python import io from collections import defaultdict import numpy as np import sys import gym import matplotlib as plot """ Il BJ è un gioco a due o più giocatori, si tratta di uno o più giocatori contro il banco. Il banco mostra una carta e poi ci da 2 carte, noi sommiamo queste due carte e possiamo decidere se prendere una carta o rimanere fermo (stick) Quando mi fermo faccio la somma delle mie carte, se ho più vi 21 punti allora ho perso, se invece meno tocca al banco e lui continua a prendere carte fino a quando arriva ad avere più o uguale 17 punti. A quel punto si ferma anche lui e chi ha di più vince. NB: Il banco non è interessato a quello che facciamo noi. POLICY: continuiamo a prendere fino a quanto arrivo a 20 o 21, la reward è +1 se ho vinto, -1 se perdo o zero se pareggio. Il valore dello stato non è più la probabilità della vittoria """ env = gym.make("Blackjack-v1", sab=True) def mc_prediction (policy, env, num_episodies, discont_factor =1.0): """ Algoritmo di predizione Monte Carlo, calcola la funzione valore per una data policy utilizzando il metodo "sampling" :param policy: una funzione che mappa un'osservazione ad una azione probabile :param env: openAI gym :param num_episodies: numero di epidosi che compongo il sample :param discont_factor: solito :return: un dizionaio che mappa lo stato nel valore valore, è una tupla il cui valore è float """ # preparo il dizionario di ritorno delle funzione # tiene traccia e conta i ritorni di ciascuno stato per calcolarne la media # NOTA: tale metodo è inefficiente returns_sum = defaultdict(float) returns_count = defaultdict(float) # funzone valore finale V = defaultdict(float) for i_episode in range (1,num_episodies+1): # stampo a quale episodio mi trovo (utile per il debug) if i_episode % 1000 == 0: print("\repisode {}/{}.".format(i_episode,num_episodies), end="") sys.stdout.flush() # genera un epidosodio rappresentato da un array di tuple composte da (stati, azionie e ricompendse) episode = [] state, info = env.reset() # resetto il gioco ovvero la carta che viene mostrata dal banco + le 2 carte che abbiam while True: probs = policy(state) # probabilità della policy # scelgo un'azione a caso dalle prob. della policy action = np.random.choice(np.arange(len(probs)), p= probs) next_state, reward, done , truncated, info = env.step(action) episode.append((state, action, reward)) if done: break state = next_state # scorro tuti gli stati visitati nell'episodio e calcola il valore medio per ogni stato states_in_episode = set ([tuple(x[0]) for x in episode]) for state in states_in_episode: first_occurence_idx = next(i for i,x in enumerate(episode) if x[0] == state) G = sum ([x[2]*(discont_factor**i) for i,x in enumerate(episode[first_occurence_idx:])]) returns_sum[state] += G returns_count[state] += 1.0 # media aritmetica V[state] = returns_sum[state] / returns_count[state] return V def sample_policy(observation): """ la policy che "sticks" ovvero si ferma se il punteggio del giocare è >= 20, altrimente prende una carta :param observation: :return: """ score, dealer_score, usable_ace = observation return [1,0] if score >= 20 else [0,1] V_10k = mc_prediction (sample_policy, env, num_episodies=10000) ``` **Metodo Temporal Difference** Il mtetodo **Temporal difference (TD)**. E' un metodo iterativo, per prima cosa devi inizializzare tutti gli stati con dei valori che potrebbero anche essere random. Partendo dallo stato s faccio **una sola azione** per arrivare nello stato s+1 e raccolgo il valore dello stato e la rimpensa corrispondente all'azione. Torno quindi allo stato in cui ero parito allo step (s) e aggiorno il valore. Come aggiorno il valore di S? V(s) = V(s) + α(R + ɣV(s+1) - Vs) dove α è il fattore di apprendimento, più è grande più do importanza al valore restituito dallo stato s+1. Il che significa sommare il valore dello stato attuale alla somma data della reward più la differenza tra il valore dello stato successivo e il valore dello stato attuale, il tutto *moltiplicato per il tasso di apprendimento alpha*. Da notare che la differenza tra V(s) e α(R + ɣV(s+1) - Vs) è detta errore, che posso variare con il tasso di apprendimento alpha. Poi si continua passando allo stato successvo e faccio la stessa cosa aggiornando V(s+1) con i valori ricavati da V(s+2). Anche quindi come con il MC faccio passare tutti gli stati S e lo faccio per N volte, anche in questo modo i valori convergeranno, dopo un numero considerevole di volte, al valore reale. Esempio. 1. setto dei valori a caso per tutti gli stati (es, zero per tutti) 2. ad ogni passo sapendo che ho una stima per ogni stato mi metto nello stato di partenza S 3. nello stato V(S) faccio l'azione arrivando nello stato S' ottenendo 14 di ricompensa 4. la mia nuova stima di V(S) sarà quindi la ricompensana + il valore di S' -> R+V(S') che essendo all'inizio V(S') varrà zero però.. 5. la stima nuova non voglio utilizzarla completamente per inserirla nello stato S cerco quindi di "poderarla" in qualche modo, quindi sottrarò dalla stima il valore dello stato S ovvero V(S) che in gergo si chiama errore e lo sommo al valore di S. 6. Riassumendo V(S) = V(S) + α(errore) dove *l'errore* è (R(S') + V(S') - V(S)) 7. faccio così per tutti gli stati dove α è un iperparametro (numero) che rappresenta quanto viene valutata affidabile la stima Nella pratica cerco di pesare il valore di V(S') tramite l'iperparametro α in considerazione del valore V(S') [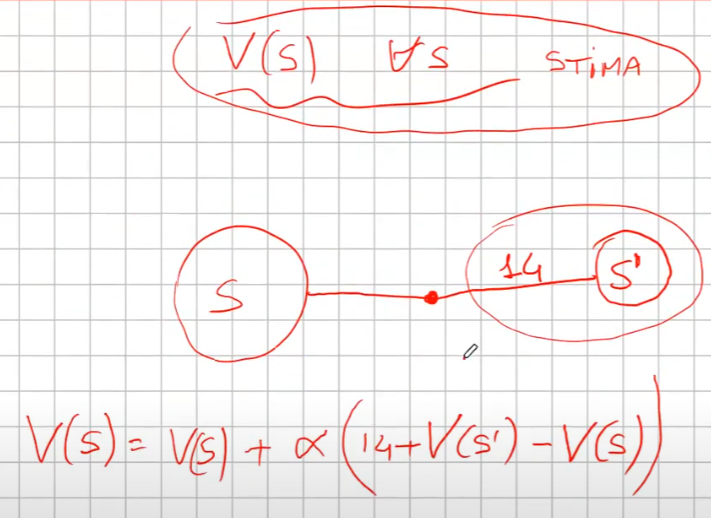](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/iNEx5gGB9hbpRVSm-image.png) **NB**: qui faccio del **boostrapping**, ovvero ad ogni passo aggiorno le stime utilizzando le stime del passo precedente. Di seguito lo pseudo-codice per la **predizione**. [](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/KJUa6XOTxEIcblXv-image.png) Dove ad ogni passo aggiorno il valore della funzione valore. Differenze e analogie tra MC e TD - MC funziona solo quando il task è episodico. (quando l'episodio finisce, in realtà esistono task infiniti) TD funziona anche con task continuativi. Nel metodo MC bisogna vedere i ritorni di tutti gli episodi, nel TD invece stiamo stimando il valore di uno stato usando la stima che avevamo prima. Ovvero, al passo K+1 si stimano i valori degli stati usando i valori del passo K e per questo motivo si parla di "differenza temporale". TD apprende ad ogni passo, MC invece deve finire l'episodio. TD è un metodo **ON-LINE** ovvero che impara ad ogni passo, mentre MC è un metodo **OFF-LINE** perchè ha bisogno di finire l'episodio aggiornare le sue stime. - Il MC sommando tutti i ritorni rischia di avere una varianza molto alta in quanto i ritorni potrebbero variare inducendo un ampliamento totale dell'errore, per contro il TD non sommando tutti i ritorni, in quanto si ferma al solo stato successivo, riduce la varianza dell'errore quindi converge prima. - TD è *distorto*, mentre MC non lo è.. un punto a favore di MC Curiosità: diffrenze tra MC , TD e programmazione dinamica (vista a inizio corso) [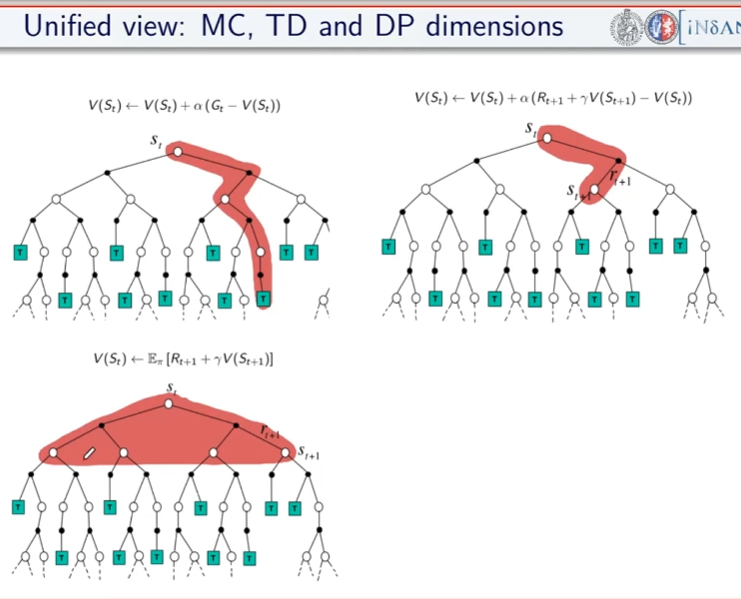](https://cms.marcocucchi.it/uploads/images/gallery/2025-01/v7BitcuvG1yD8A2d-image.png) ##### Model free -> miglioramento e controllo Nella predizione, viene sempre applicata la stessa policy, ovviamente anche la policy deve migliorare nel tempo, ecco che quindi dopo il ciclo di predizione deve seguire il ciclo di miglioramento e controllo della policy. Questo significa che i valori degli stati migliorerano nella fase di predizione e che la scelta degli stati stessi, conseguenza del miglioramento della policy, cambia in quanto le azioni cambiano (in genere) con il cambio della policy per via del miglioramento della stessa. Esistono due famiglie di metodi per fare miglioramento e controllo, e sono: 1. On-policy MC control (controllo = iterazione del miglioramento con la predizione) 2. On-policy TD control (controllo = iterazione del miglioramento con la predizione) 3. Off-policy prediction 4. Off-policy control Che differenza c'è tra i metodi on-policy e off-policy? ##### On-policy Questi metodi nella pratica utilizzano la stessa policy migliorandola. Ovvero agendo "greedy" vengono scelte le azioni che massimizzano il risultato e che ne migliorarno la policy, ma, la policy seppur migliorata è sempre la stessa. ##### Off-policy Con i metodi off-policy viene introdotto un fattore di "**esplorazione**" che in qualche modo crea delle policy nuove "*parallele*" a quella che stiamo migliorando, per poi metterle in qualche modo a confronto ed eventualmente cambiare la policy con quella nuova trovata tramite esplorazione. ##### General Policy Iteration Come miglioro la policy? **Basta fare il calcolo della funzione valore stato-azione Q(s,a) anzichè il valore della stato azione V(s)** in modo da ottenere la probabilità dell'azione. Ok, ma questo non serve realmente per migliorare la policy in quanto agisce sempre in manidera greedy sulla stessa policy. Per migliorare la policy quindi è necessario scegliere "ogni tanto" delle azioni che non sono greedy in modo da effettuare **l'esplorazione**. Ricordo che per miglioramento della policy si intende: "**il valore della nuova policy è migliore della precedente in tutti gli stati**". ##### Dilemma dell'esplorazione vs sfruttamento Di qui il metodo "**epsisodio greedy**" (**ε-greedy**) , dove epsilon è la percentuale di scelta di una azione casuale. (in genere un valore piccolo es. 10%) Bisogna quindi lavorare con policy stato-azione con probabilità > 0 in particolare la percentuale deve essere maggiore di **ε**. (questo concetto non mi è chiaro) [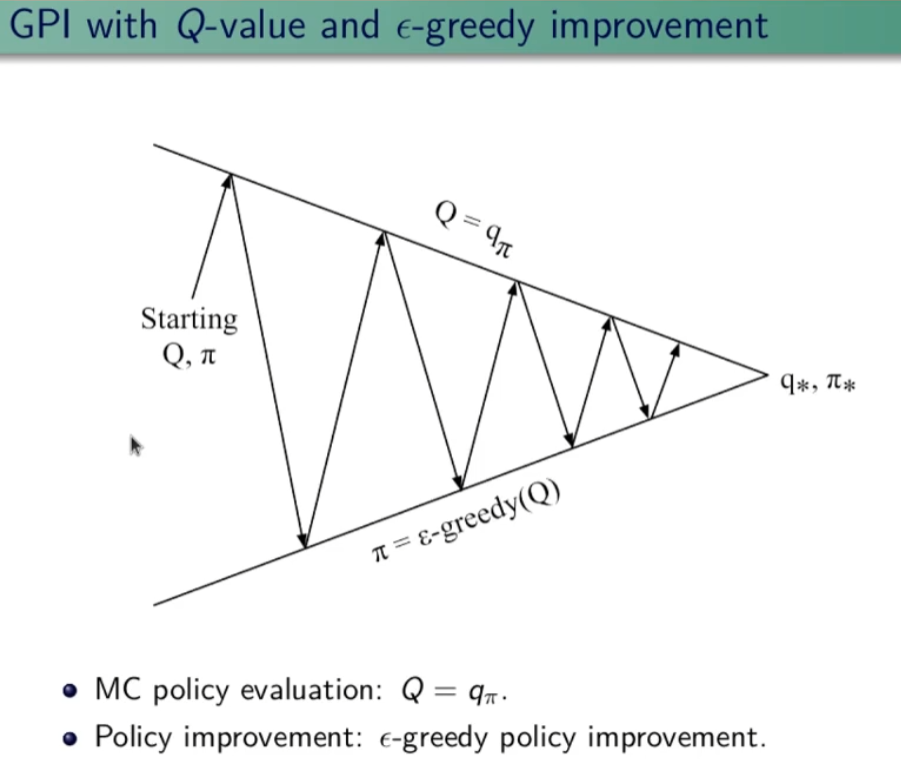](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/eRA9eWRjqnztGb43-screenshot.png) ##### GL-IE (teorema generale) Come deve funzionare l'algoritmo epsilon greedy? L'algoritmo da utilizzare è il GLIE che, per definizione, converge alla policy ottimale, ma cosa significa GLIE e come funziona? **GL**= *greedy in the limit*: si richiede che nella policy iteration (valutazione della policy e miglioramento) che il miglioramento **tenda** ad una policy greedy. Che significa che la policy a cui si converge è greedy. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/3TRvqtsOPoHBIh6F-screenshot.png) **IE**= infinite exploration: tutte le coppie stato-azione siano visitate dall'algoritmo infinite volte. (richiesto dalla legge dei numeri) [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/dePn57Qp6TDci55h-screenshot.png) Se GL e IE sono confermati ed implementati allora l'algoritmo è **ottimale**. Ma come fare? La risposta è implementare l'algoritmo espisolon-greedy facendo in modo che epsilon decresca al crescere degli episodi k. Il che significa che ad un certo punto epsilon tenderà a zero. ##### On-policy MC (Monte Carlo) Per calcolare la policy e migliorarla va usato il Q-Value. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/21nqG3fL7yfT6Vz5-screenshot.png) ##### Partenze esplorative (exploring starts) Un altro algorino GLIE è per es. quello che implementa le "partenze esplorative" ovvero la scelta causale di uno stato di partenza. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/UkfnSvUzZK4tCFB1-screenshot.png) ##### On-policy TD (temporal difference) Anche per il TD dovremmo utilizzare il Q-Vaue, l'algoritmo da utilzzare si chiama "*Sarsa*". Si chiama così perchè parte dalla coppia Stato-Azione vede ricompensa abbiamo ottenuto, vede lo stato successivo ottenuto, prende una nuova azione (quindi va in un nuovo nodo Stato-Azione) e si ferma. Ricordo che il concetto di stato stato nel "model free" è sempre riferito allo Stato-Azione. (vedi diagramma di backup sotto riportata) [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/3oTaR5yQ4my7RsTL-cattura.PNG) *Predizione* Per la fase di predizione TD, quando arrivo nel nuovo nodo vedo il valore Q-Value associato allo stato-azione di arrivo. Anche qui vale la formula classica di calcolo del valore stato per TD con la differenza che, essendo model free, dovremo utilizzare il Q-Value e quindi la combianazine Stato-Azione. Anche qui alpha rappresenta il fattore di apprendimento, la tabella dei q-value va anche qui va inizializzata con valori a piacimento, alla fine dei vari episodi il tutto dovrebbe convergere. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/0xAOGcXHhaxcFvAy-cattura.PNG) [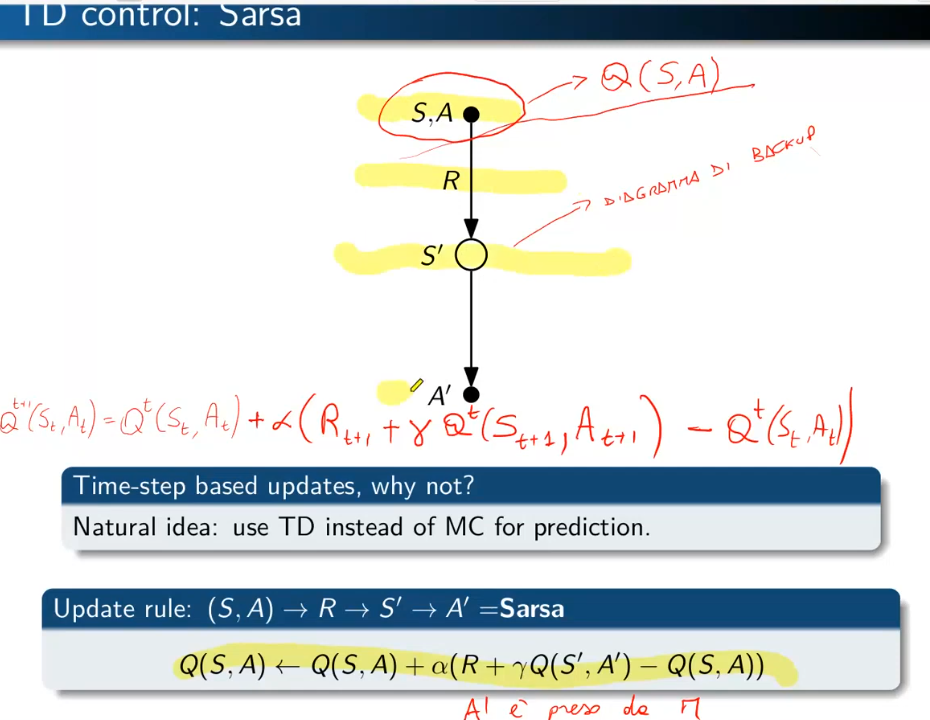](https://cms.marcocucchi.it/uploads/images/gallery/2025-05/TZfJ1GxqfJHUDuNg-image.png) e quindi il diagramma di convergenza [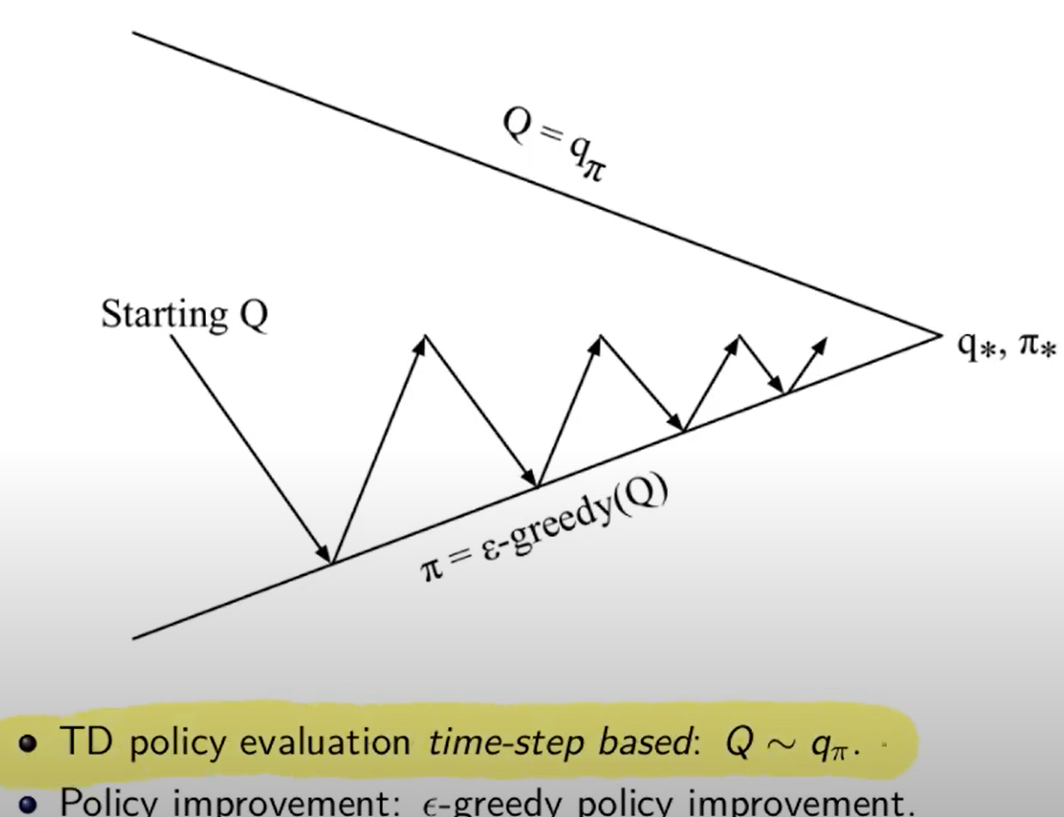](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/U3x9POyYk0HBnoES-cattura.PNG) e lo psudo-codice: Scegliamo il tasso di apprendimento (alpha), inizializziamo la tabella degli stati-azioni facendo attenzione a impostare il valore dello stato terminale a *zero*. (altrimenti avremo una distorsione nel valore iniziale che non verrà mai corretta) *Controllo epsilon-greedy* Per migliorare la policy utilizzo il metodo epsiolo-greedy ovvero partendo dalla matrice dove ogni cella contine il valori stato-azione... Scegliamo la partenza, scegliamo un'azione dallo stato S utilizzando una policy epsilon-greedy. Quando lo stato è terminale riconciamo. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/1K4y8Fj70LPftzo3-cattura.PNG) Funziona? si purchè siano soddisfatte delle ipotesi (teoriche) che sono: 1\) la successione di policy che ottengo devono tutte darmi tutte esplorazini infinite (soft) e devono essere greedy-in-limit, ovvero con espilon-greedy non costante, cioè che deve tendere - all'aumentare di k - al valore zero 2\) il tasso di apprendimento alpha che tende allo zero velocemente ma non troppo.. Però queste due condizioni teoriche non vengono quasi mai rispettate, quindi in genere si tengono come costanti Esiste anche al versione a N step di Sarsa: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/0yPTcJlLwGu3isWX-cattura.PNG) e questo lo pseudo codice: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/5i0mu5BZtNujhh67-cattura.PNG) #### Metodi off-policy Con il metodo off-policy usiamo una policy "**u**" (mu) detta di "esplorazione" per fare un'esperienza (traiettoria) che ci dice come è fatto l'ambiente, uso questa esperienza per valutarne un'altra detta policy "target" "**pi**" (di miglioramento) e le confronto. Quindi nella pratica c'è una policy che **impara **e una che fa **esperienza**. (esperinza detta anche policy comportamento) *Difetti* - questi metodi hanno una varianza molto alta e quindi convergenza molto lenta - quando utilizzati + metodi non tabellari (rete neurali) + bootstrapping = non funziona *Vantaggi* - risolve il dilemma esplorazione-sfruttamento molto bene - l'esperienza pregressa può essere acquisita (importata) dall'esterno ed essere sfruttata - posso riusare quando voglio le esperienza generata nelle policy precedenti - posso imparare policy multiple ovvero seguo una policy da questa ne derivo N che possono essere tutte ottimali *Prerequisito di utilizzo* Se un'azione ha probabilità positiva di essere scelta allora deve essere positiva anche la probabilità di scelta di un'azione della policy di comportamento, ovvero: pi(s,a) > 0 -> u(s,a) > 0 *Quindi la policy che impariamo può/deve essere deterministica, mentre la policy di comportamento deve essere stocastica.* *Predizione: Regole di update dei metodi di predizione off-policy:* [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/MZ1fAH1k4uSCxNmh-cattura.PNG) Viene suggerito di non considerare il metodo off-policy con MC in quanto, per via dei troppi stati da esplorare nell'episodio, viene generata troppa varianza dei valori, il che rende la formula molto complicata. Invece il metodo off-polcy funziona bene con il temporal difference, in quanto il rapporto tra u (mu) e pi risulta essere un rapporto tra probabilità il che non presenta il difetto della varianza. #### Predizine + miglioramento dei metodi off-policy ##### Controllo MC Nonostante MC non sia forse il metodo migliore nell'ambito degli off-policy, l'algoritmo cmq esiste, ne riporto lo pseudo codice sotto: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-08/s12Zqvem7tLCNNdn-cattura.PNG) Questo algoritmo nel 2019 ancora non era stato ben esplorato, per cui per in questo corso non verrà approfondito. #### Controllo TD Quando si lavora con i metodi *on-policy*, viene utilizzata la stessa policy per esplorare gli stati e la si faceva migliorare e tende ad essere la policy ottimale. Si era poi deciso che per mantere una policy che sia in grado, da un lato di migliorare in maniera greedy e che nel contempo possa anche eplorare, di utilizzare le epsilon-greedy ovvero che facesse anche dell'esplorazione mentre migliora. A questo punto separiamo le due policy, ovvero scegliamo una poloicy che esplora e usiamo l'esperienza fatta con questa per aggiornare un'altra policy, che è quella che piano piano diventa migliore e che a questo punto può essere totalmente greedy. Il rapporto tra le due policy si chiama "rapporto di verosimilianza". Quando il rapporto tra i due è grande (pi/u) ##### Controllo Q-learning I Q-learning sono una famiglia di algoritmi, dove l'azione nel target la scelgo con la policy pi di improvement. [](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/Ar1tJndfpsS4zrYp-screenshot.png) che migliorata si può scrivere: [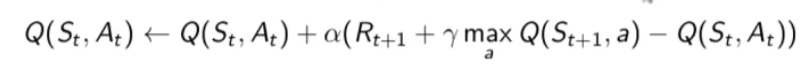](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/C2ZG0d6YKfbwZLwq-screenshot.png) dove la policy pi è scelta come max di Q ovvero in maniera greedy, mentre le altre azioni sono scelte con la policy "mu" esplorativa. Nella pratica l'azione A viene scelta in maniera epsilo-greedy con la policu "mu" [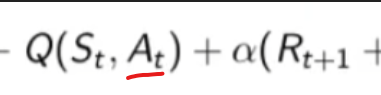 ](https://cms.marcocucchi.it/uploads/images/gallery/2025-05/TVaa9YodW23eLhg8-image.png) mentre l'azione dello stato di arrivo St+1 è scelta con la polict greedy [](https://cms.marcocucchi.it/uploads/images/gallery/2025-05/CuGjbNm7SA7HVpeW-image.png) [](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/y4Kat0RoWQp8vLem-screenshot.png) Ippotizziamo ora questo esercizio, ovvero un mondo griglia con un burrone come sotto riportato: [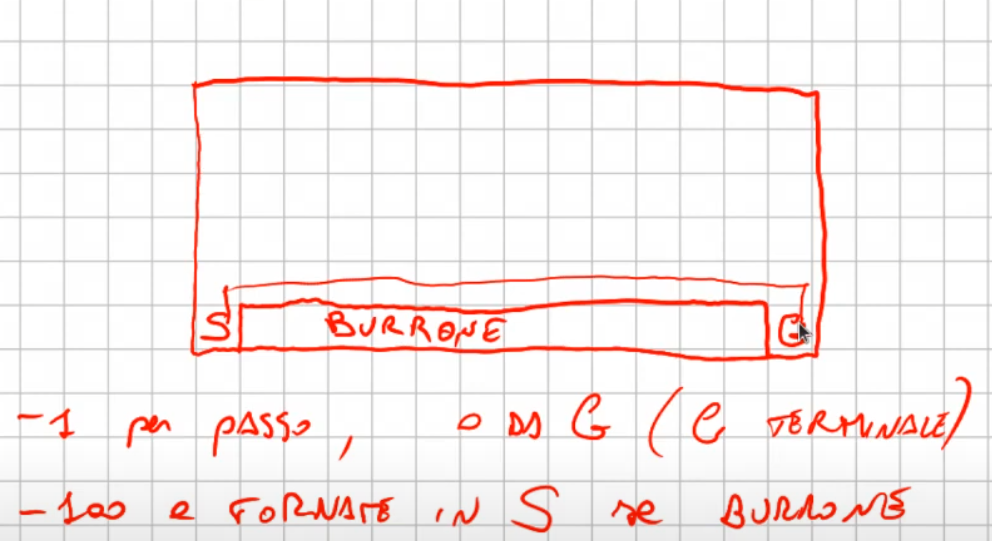](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/W2ehxBfw9WOKkUw0-screenshot.png) Vogliamo applicare l'algoritmo Sarsa e l'algoritmo Q-Learning. Sarsa è epsilo-greedy mentre Q-Learning è greedy. Quanto emerge viene riportato sotto: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/NavP9ZcxuiOHz30b-screenshot.png) ovvero che Sarsa (blu) trova un percorso sub-ottimale, questo perchè essendo epsilong-greedy, tende a "rischiare" di meno e quindi sbagliare di meno. Mentre invece Q-learning è si ottimale, ma tende a rischiare di più. Q-Learning è quindi meglio? Dipende, se abbiamo a che fare con delle simultazioni, allora è sicuramente meglio, se invece abbiamo a che fare con il mondo reale dove i rischi sono reali allora è meglio scegliere una soluzione più "safe" come quella di Sarsa. Se quindi misuro la somma delle ricompense il Q-learning ne riceve meno in quanto appunto rischia di più in quanto, nell'esempio tende a cadere maggiormente nel burrone. (vedi gradico sotto riportato) [](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/apZxVfeO9mFqoL8w-screenshot.png) ##### Miglioramento della policy target pi Q-Learning (detto Sarsa Atteso o Expeted) Target Q-Learning (predizione ovvero fissato pi) -> R + gamma\*Q(S',A') dove A' è campionata di pi di S' che si scrive (A=pi(.|S') ovvero: [](https://cms.marcocucchi.it/uploads/images/gallery/2023-09/4JYFNki6VKNCMlj0-screenshot.png) questo algoritmo migliora il Sarsa On-policy e il Q-Learning Off-policy. Questo è un metodo che stima il modello, lo impara e lo usa man mano che lo imparano, sono detti "model based". # Sessione 1 (v2) Premessa In questa seconda versione del corso ho deciso di soffermarmi sui concetti che non avevo colto nella prima versione del corso stesso. Le nozioni del primo corso rimangono valide e sono da utilizzare come integrazione di questa seconda versione. La V2 quindi sintetizza i concetti che reputo più importanti.